Google Trendから見る都道府県別幸福度
という面白い取り組み。
はしょって言えば、
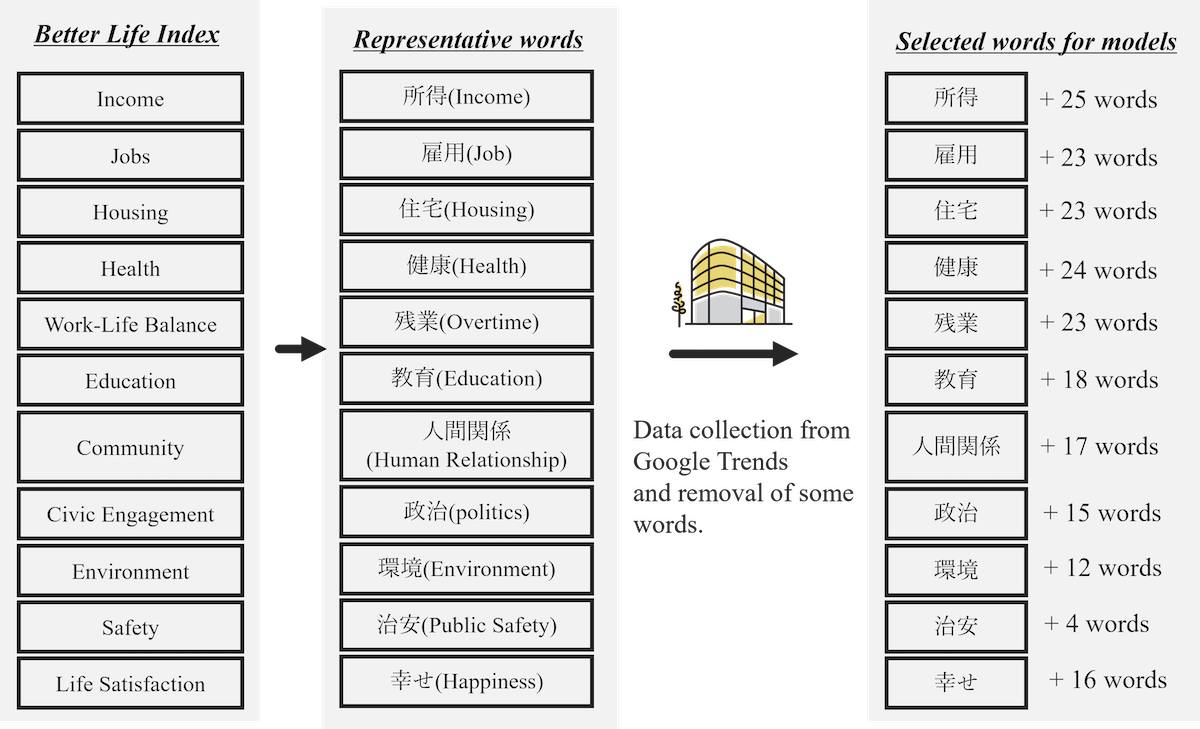
・OECDのBetter Life Indexを元に特徴となるワードを選定
・そのワードのGoogle Trendsを都道府県別に見て、幸福度を算出
・実際に測ったデータと併せて見ても、Google Trendsから算出したデータではだいぶ予測出来ていた。
みたいな感じ。
ーーー
あと、
この手の話で著名なのが、Hedonometerというサイト。
日本語はないのですが、10個くらいの言語でのTwitter分析結果を、公開頂いています。(ポジティブな投稿度)
クリスマスが、一年でも一番盛り上がっていたり、ここ数年で起きた大きな事件と幸福度の関係なんかも面白いです。
ウクライナでの戦争が始まった時は、ウクライナ以上に、ロシアの幸福度の方が落ちていたりもしていました。
※参考_Hedonometer
https://hedonometer.org/timeseries/en_all/
Twitterでの分析
ーーー
■AIサマリー
この研究の主な内容と知見を以下にまとめます:
目的:
インターネット検索データを使用して、日本の都道府県レベルでの包括的な幸福度指標(Regional Well-Being Index: RWI)を予測するモデルを開発すること。
より迅速で費用対効果の高い幸福度評価手法を提案すること。
方法:
アウトカム変数として、OECDのBetter Life Indexに基づく日本の47都道府県のRWIを使用
Google Trendsから収集した検索ボリュームデータを予測変数として使用
Elastic Netという機械学習手法を用いてモデルを構築
2010-2016年のデータで学習し、2019年のデータでテスト
主な結果:
モデルは高い予測精度を達成 (テストデータでR² = 0.665)
これは先行研究と比較して良好な結果
所得、雇用、住宅、健康など11の領域について2-13の変数を選択
研究の意義:
従来の大規模調査に比べて、より迅速で低コストな幸福度評価が可能に
政策立案者が適時に住民の幸福度を評価できる
他国でも応用可能な手法を提示
限界:
生態学的研究のため個人レベルでの関連は評価できない
検索語と幸福度の因果関係は不明
Google Trendsデータの制約
この研究は、ウェブデータを活用した幸福度評価の新しいアプローチを提示し、より効率的な政策立案に貢献する可能性を示しています。
ーーー
インターネット検索エンジンの検索ボリュームを用いた日本における都道府県レベルの幸福度指標の予測:インフォデミオロジー研究
Predicting Prefecture-Level Well-Being Indicators in Japan Using Search Volumes in Internet Search Engines: Infodemiology Study
2024/11/11,Journal of Medical Internet Research
https://www.jmir.org/2024/1/e64555/
背景:
近年、国家政府や国際機関による幸福度指標の採用は、国家統治や社会の進歩を評価するための重要なツールとして浮上しています。伝統的に、幸福度は主に国内総生産などの経済指標で測定されてきましたが、社会経済的格差、生活満足度、健康状態など、多面的な幸福度を捉えるには不十分です。主観的および客観的な尺度の両方を含む現在の幸福度指標は、より広範な評価を提供しますが、調査コストが高いことや、国内の地域レベルでの評価が難しいことなどの課題に直面しています。幸福度指標の代替ソースとしてのウェブログデータの出現は、より費用対効果が高く、タイムリーで、偏りの少ない評価の可能性を提供します。
客観的:
この研究は、インターネット検索データを使用して日本の地域レベルの幸福度指標を予測するモデルを開発し、政策立案者に、国民の幸福度を評価し、情報に基づいた意思決定を行うための、よりアクセスしやすく費用対効果の高いツールを提供することを目的としました。
方法:
本研究では、2010年、2013年、2016年、2019年の47都道府県の幸福度を評価する日本の地域幸福度指数(RWI)を結果変数として使用しました。RWIには、収入、仕事、生活満足度など11の領域にわたる主観的指標と客観的指標の両方を統合した包括的なアプローチが含まれています。予測変数には、各領域に関連する単語のGoogleトレンドからのzスコア正規化相対検索量(RSV)データが含まれています。関連性を保証するために、無関係な単語は分析から除外されました。Elastic Net手法は、RSVを使用してRWIを予測するために適用され、αはリッジ効果とラッソ効果のバランスを取り、λはそれらの強度を調整しました。モデルはクロスバリデーションによって最適化され、予測誤差を最小限に抑えるための正則化パラメータの最適な組み合わせと強度が決定されました。
結果:
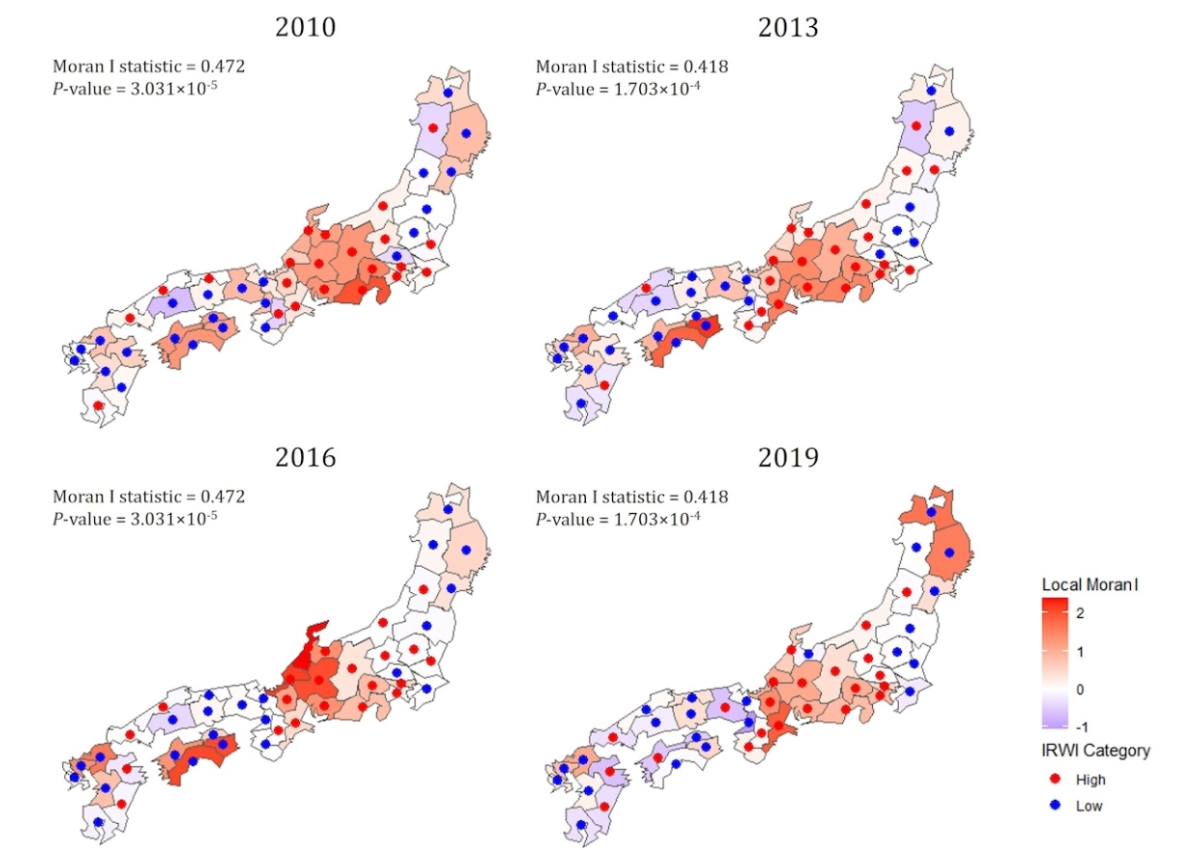
Google トレンド データの分析により、RWI ドメインに関連する 275 語が得られ、無関係な用語を除外した後、211 語の RSV が収集されました。2010 年、2013 年、2016 年、2019 年のこれらの語の平均検索頻度は -1.587 ~ 3.902 の範囲で、SD は 3.025 ~ 0.053 でした。最適な Elastic Net モデル (α=0.1、λ=0.906、RMSE=1.290、R 2 =0.904) は、2010 ~ 2016 年のトレーニング データとドメインあたり 2 ~ 13 個の変数を使用して構築されました。2019 年のテスト データに適用すると、RMSE は 2.328、R 2は 0.665 でした。
結論:
この研究は、Elastic Net 機械学習法を通じてインターネット検索ログデータを使用することで、日本の都道府県における RWI を高精度に予測し、従来の調査手法に代わる迅速かつ費用対効果の高い方法を提供するという有効性を実証しています。この研究は、この方法論が、幸福度の向上を目的とした証拠に基づく政策立案のための基礎データを提供する可能性を強調しています。



本研究のウェルビーイング小話はこちら😊
はぴテク相談室:Google Trendから見る都道府県別幸福度
https://wellbeing-archive.pages.dev/posts/2024-11-16-1731721140/