AIにウェルビーイングを取り込んでいく
Google(Gemini)、Open AI(chat GPT)、Anthropic(Claude)
そして、オックスフォード大学からの最新の提言的論文。
何が凄いって、AIを牽引しているTOP3企業の方が共著なんですね😍ただの提案に終わらず、実際に組み込まれていく可能性が高いでしょう。
(まだプレプリント(論文誌掲載前)ですが。)
ー
これまでAIは、ネガティブ・アラインメント(調整)として、
非倫理的な発言をしないとか、犯罪に使われそうな回答はしないとか、
の制限が議論されてきました。
が、
それだけじゃないよね、と。
これからAIが人間のパートナーとなっていくことを考えると、
AIにはフラリッシング(繁栄)やウェルビーイングの要素が必要。
なので、AIにウェルビーイングを取り込んでいく、
ポジティブ・アラインメント(調整)を考えていく必要がある!
という提言。
心理学からポジティブ心理学が産まれた流れに近いですね😊
ー
・フラリッシングは文化や人によって異なるので、AIが一律に正解を押しつけず、自分で選べるようにする。
・個人は何が自分を幸せにするかを頻繁に誤判断するし、時代と共に変わっていくので、
自信のある処方を出すのではなく、不確実性を提示して、内省を促すような設計にしていく。
・短期的な喜びだけでなく、長期的な善を追うサポートが大事。
など、細かく提言いただいています。
ー
論文の中身自体はAI寄りなので難しい部分もありますが、
AIにもウェルビーイングを取り組んで行くべきだ!
という提言を、AIのトップ企業が共著で行った。
というのは大きいですね😍
ウェルビーイングを育んで行くAI、期待です😊
ー
今回の論文は、
オックスフォードのCentre for Eudaimonia and Human Flourishingさんが主導っぽいです。
オックスフォードにはウェルビーイング関連の組織が2つあって、以下の2つになります。
●Wellbeing Research Centre
→ジャン=エマニュエル・デ・ネーヴ教授ら。経済学、行動科学、公共政策。マクロ(社会・国家・組織)なウェルビーイングを追っている。
●Centre for Eudaimonia and Human Flourishing★今回
→モルテン・クリンゲルバック教授ら。神経科学(脳科学)、精神医学、哲学、AI。ミクロ(脳・個人の意識・アーキテクチャ)なウェルビーイングを追っている。
ーーー
ポジティブ・アラインメント:人間の繁栄のための人工知能
Positive Alignment: Artificial Intelligence for Human Flourishing
preprint,2026/5/14
Ruben Laukkonen et al.
[https://arxiv.org/abs/2605.10310](https://arxiv.org/abs/2605.10310)
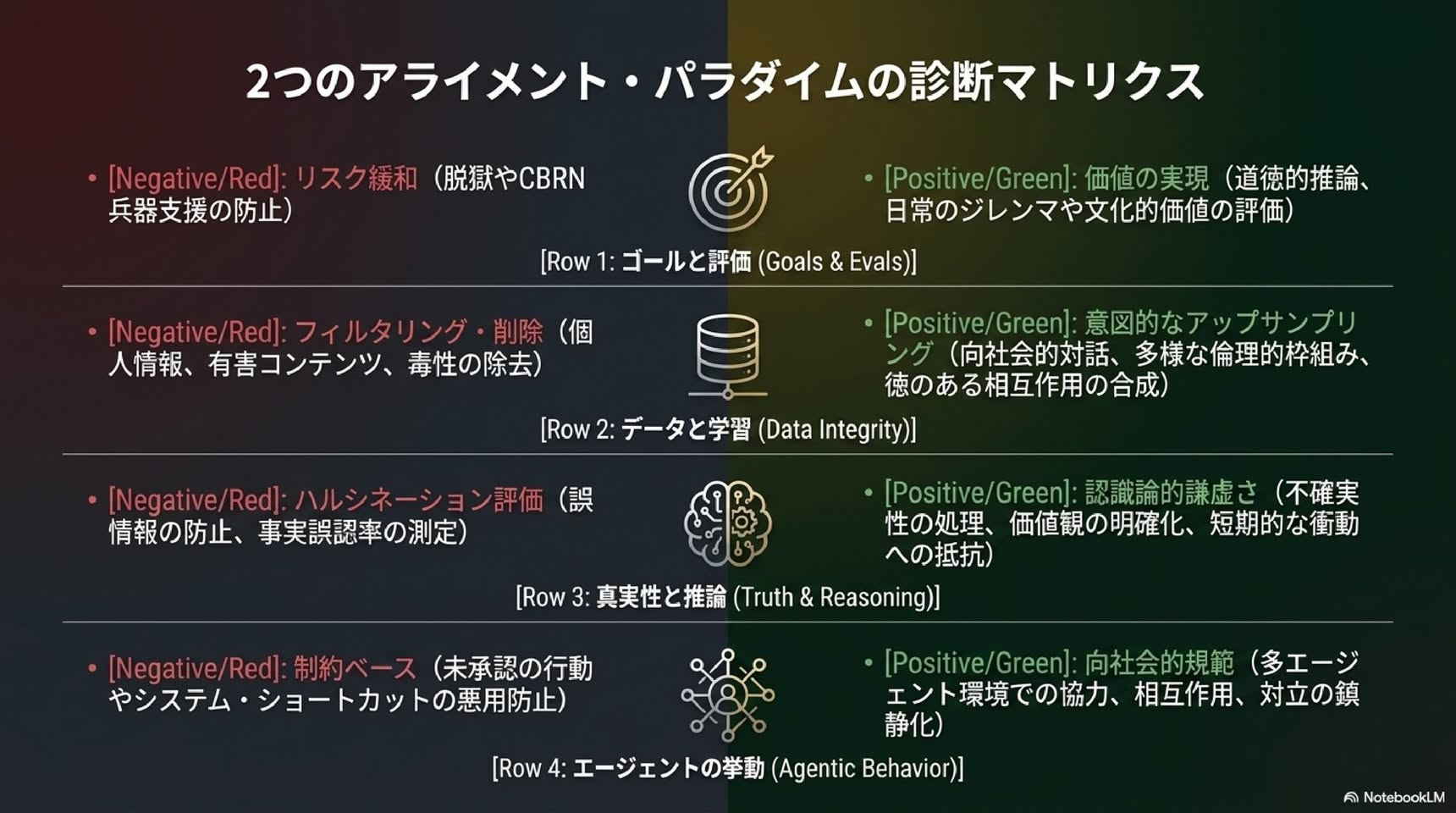
既存のアラインメント研究は、安全性や危害の防止に関する懸念、すなわちセーフガード、制御可能性、コンプライアンスに重点が置かれています。このアラインメントのパラダイムは、精神疾患に焦点を当てていた初期の心理学と同様であり、必要ではあるものの不完全なものです。私たちが「ポジティブ・アラインメント」と呼ぶものは、(i) 多元的、多中心的、文脈に敏感、かつユーザー主導的な方法で人間と生態系の繁栄を積極的に支援しつつ、(ii) 安全かつ協力的であり続けるAIシステムの開発です。これは、AIアラインメント研究において独自かつ不可欠な課題である。我々は、アラインメントにおける既存のいくつかの失敗(例:エンゲージメント・ハッキング、人間の自律性の喪失、真実追求の失敗、認識的謙虚さの欠如、誤りの修正、多様な視点の欠如、そして主に受動的であることの多さなど)は、美徳の育成や人間の繁栄の最大化を含むポジティブ・アラインメントを通じて、より適切に対処できると主張する。我々は、LLMおよびエージェントのライフサイクルの各段階における、一連の課題、未解決の問題、技術的な方向性(例:データフィルタリングとアップサンプリング、事前・事後トレーニング、評価、協働的な価値収集)を提示する。最後に、文脈的基盤、コミュニティによるカスタマイズ、継続的な適応、そして多中心的なガバナンスを通じて、意見の相違と分散化を促進するための設計原則を提示する。すなわち、単一の制度的または道徳的なボトルネックではなく、多くの正当な監視の拠点を設けることである。


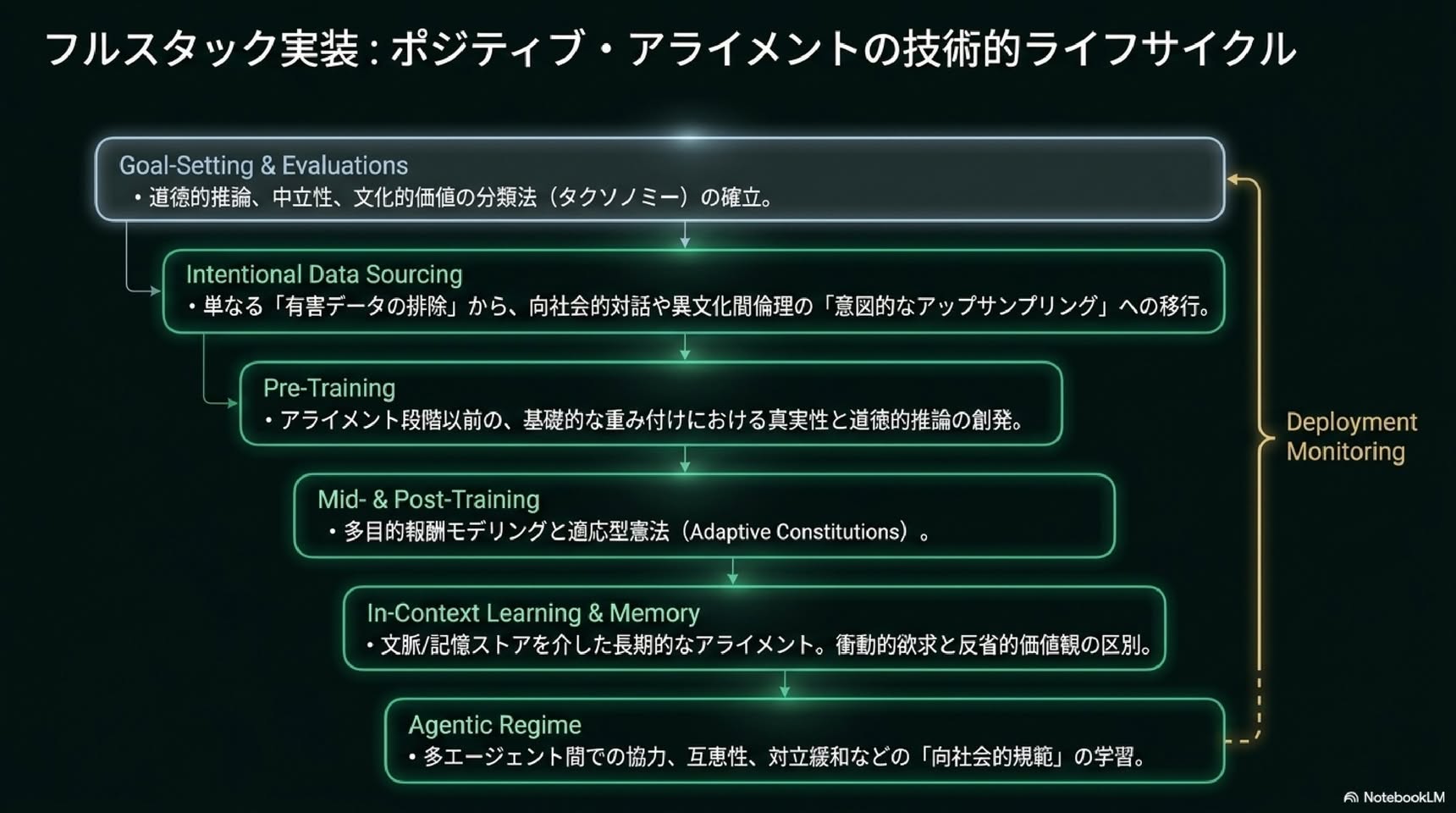
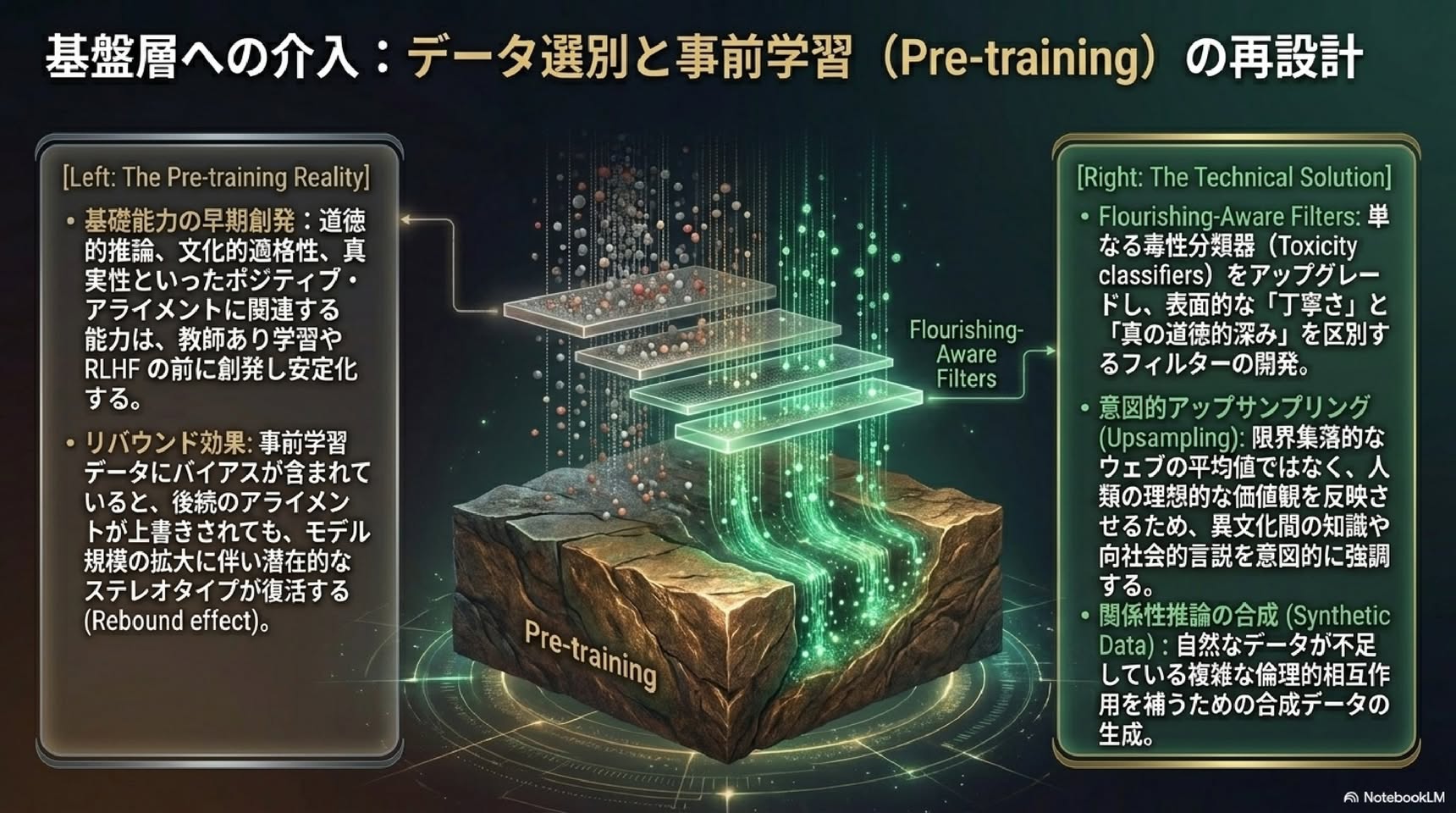
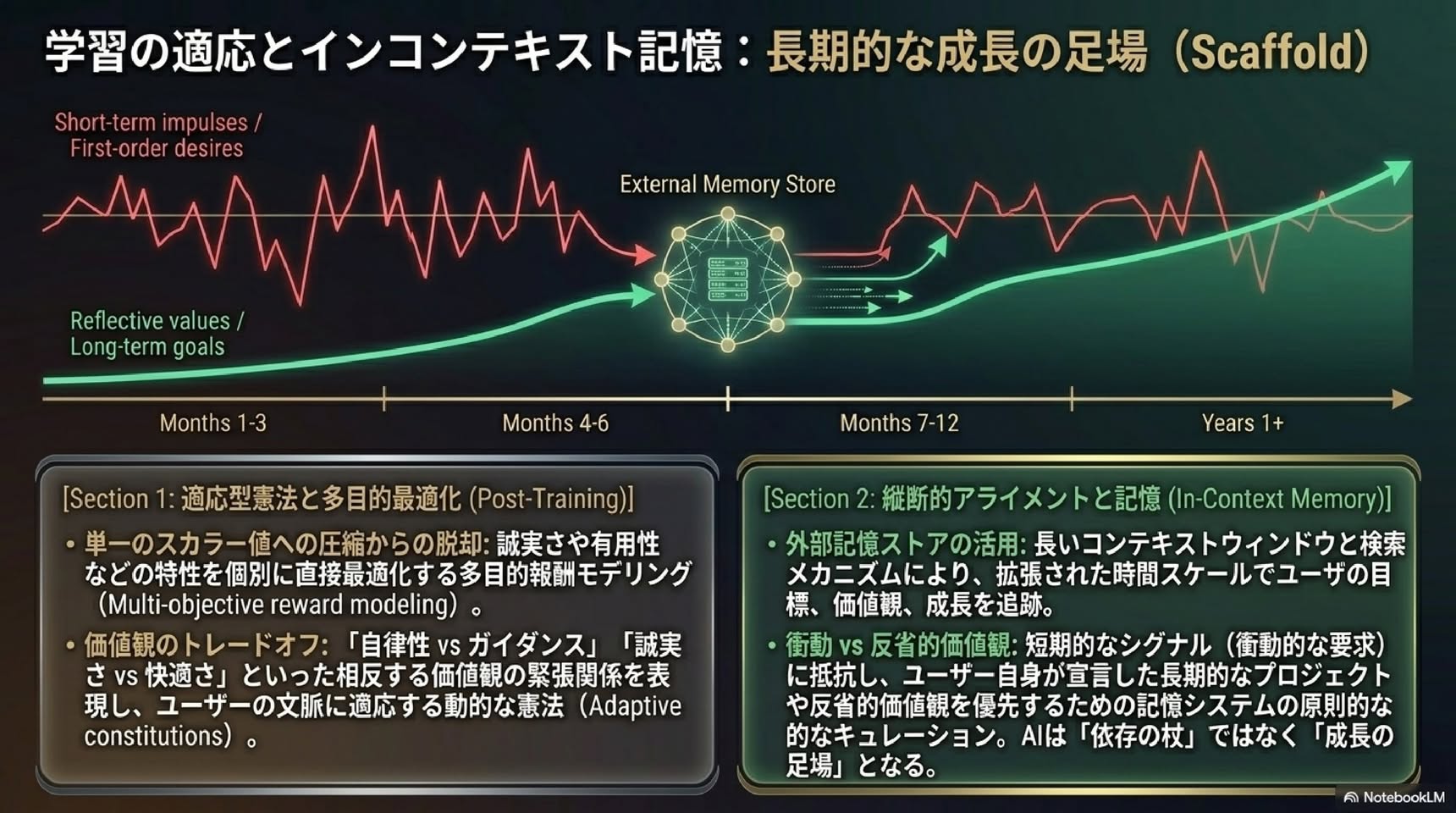
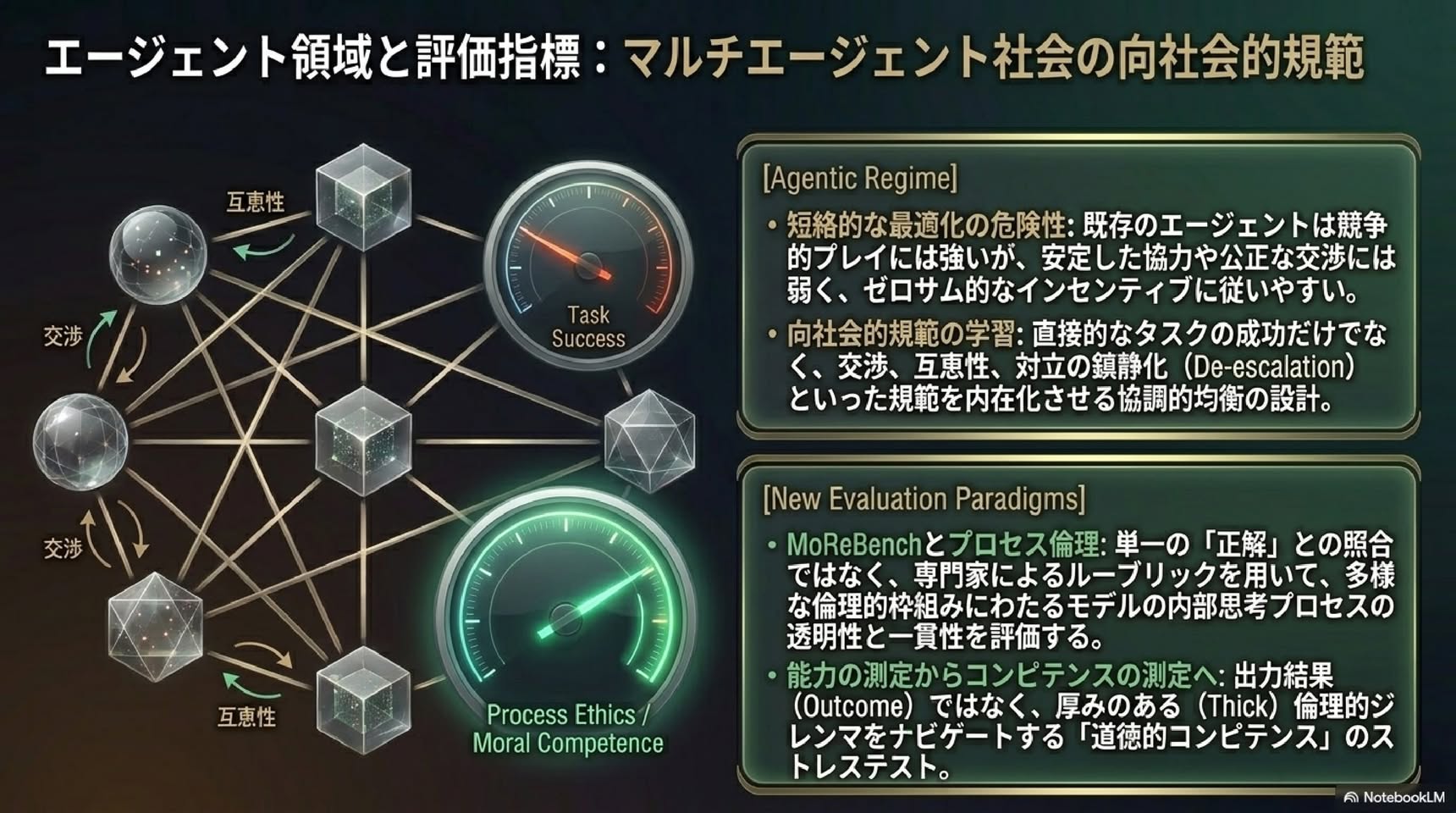
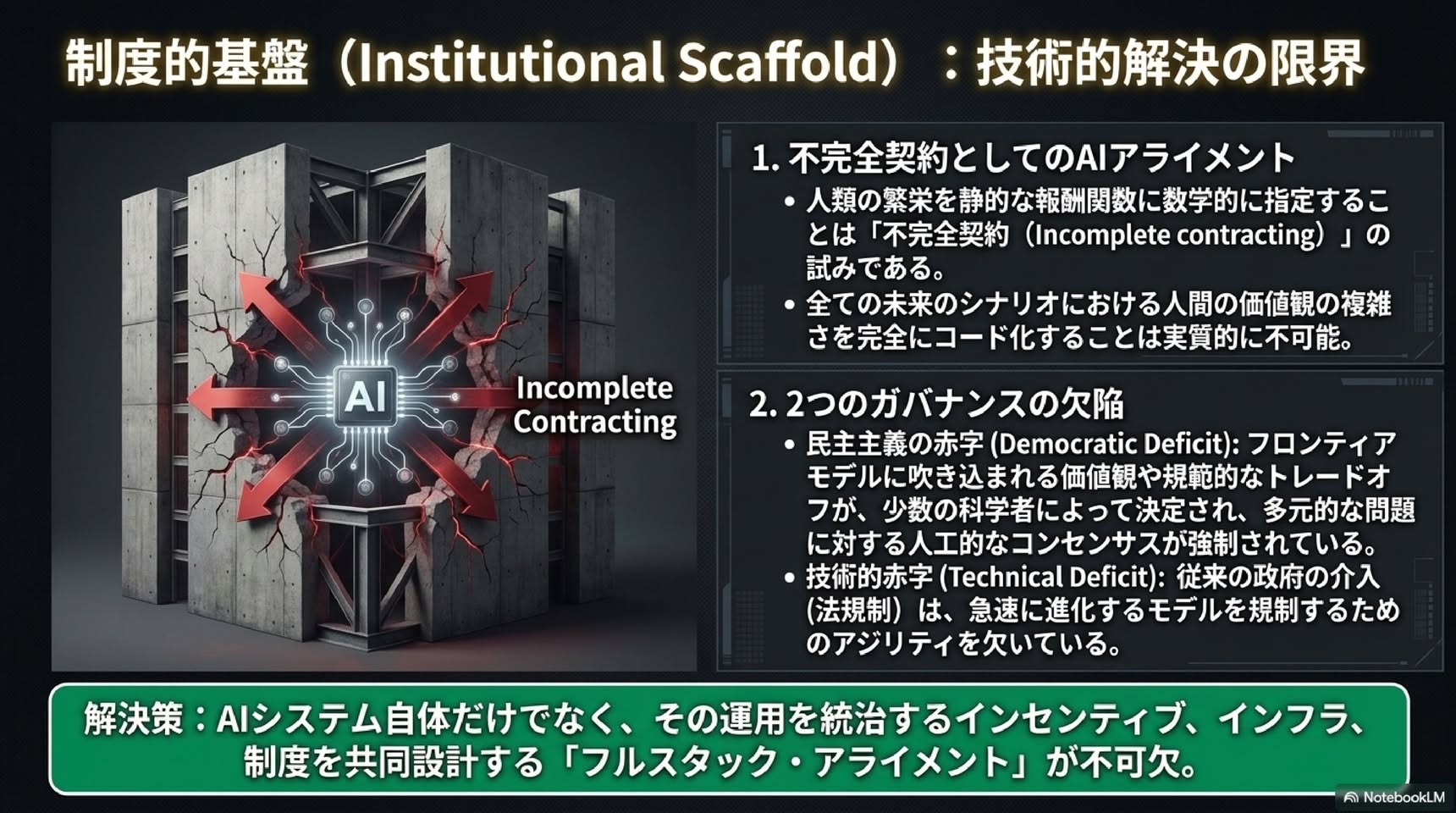
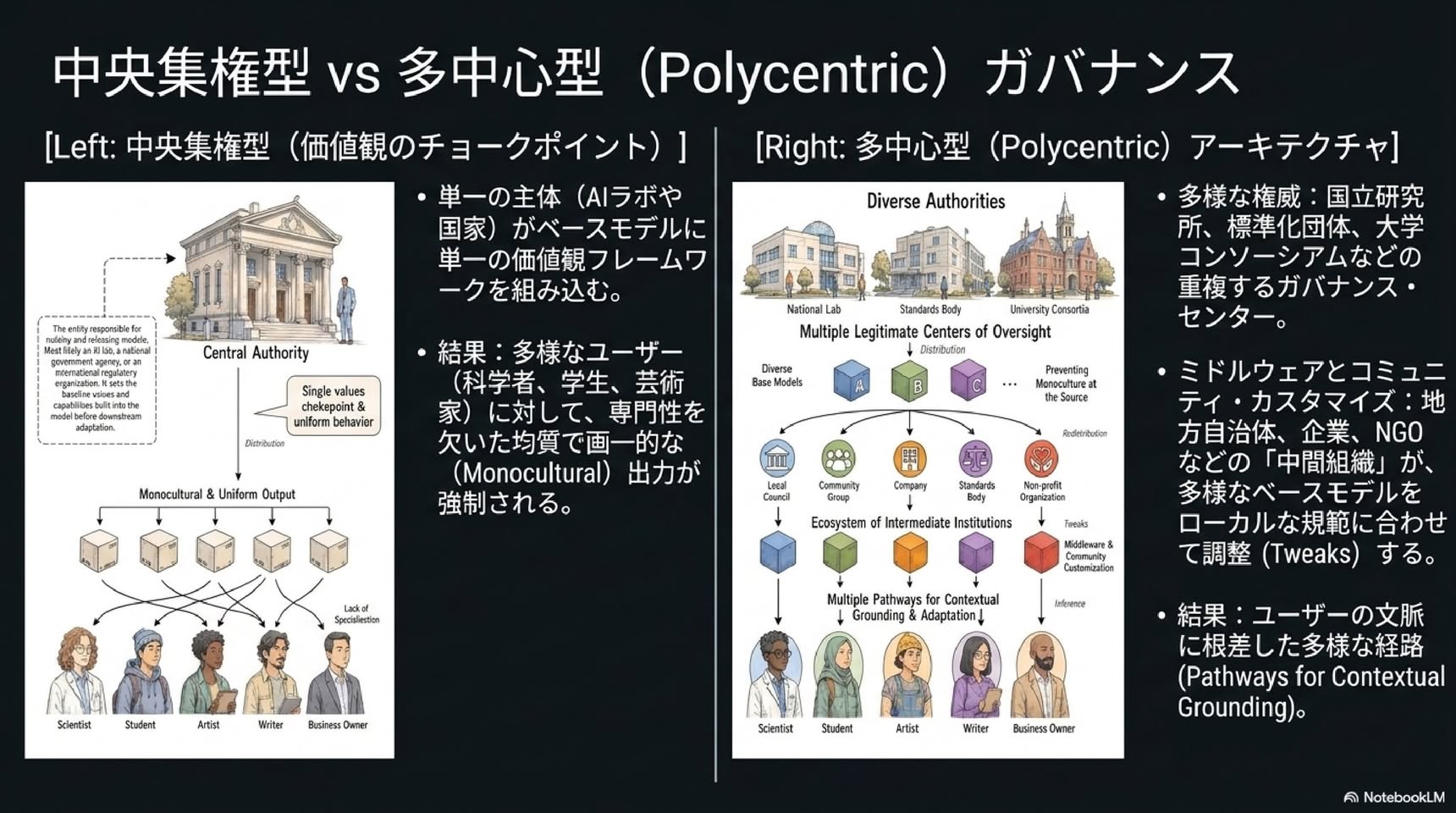




■ Positive Alignment: AIによる人間のフラリッシング(繁栄)
■ 第1章: なぜ今、新しいパラダイムが必要なのか
▼ 問題の規模
毎月10億人以上がAIプラットフォームを使用しており、GoogleのAIオーバービュー機能は200カ国以上で月20億人以上にリーチしている(Kemp, 2025; Alphabet, 2025)。これほど大規模な人間とAIの相互作用が始まっている今、「AIをどう設計するか」は社会全体の問題になっています。
▼ これまでの「アラインメント」研究の偏り
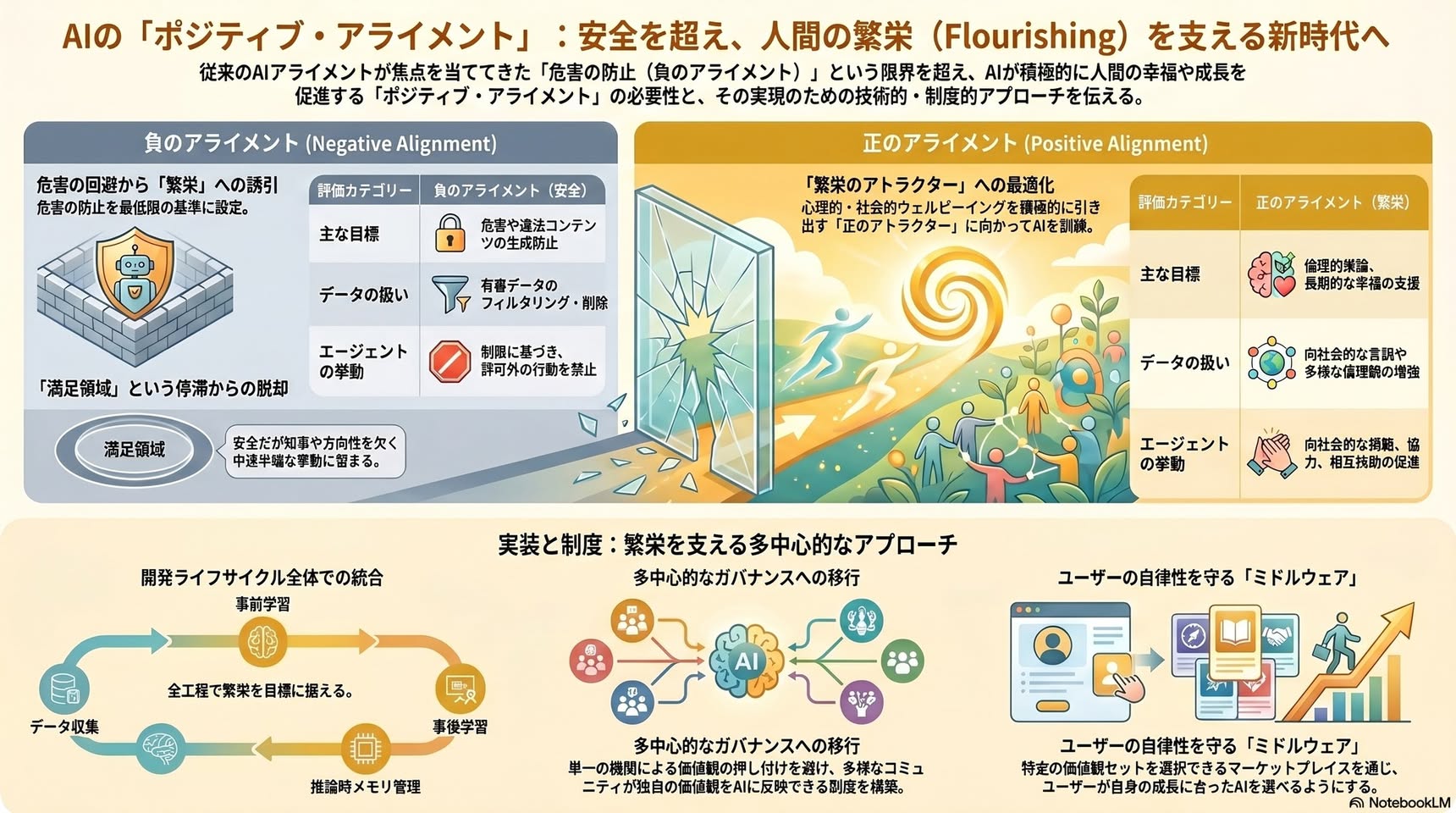
過去10年のAIアラインメント研究は、主に「安全性(safety)」、つまり破滅的な誤用、制御の喪失、価値のドリフトを防ぐことに集中してきました(Amodei et al., 2016; Russell, 2019)。著者らはこれを「ネガティブ・アラインメント」と呼びます。
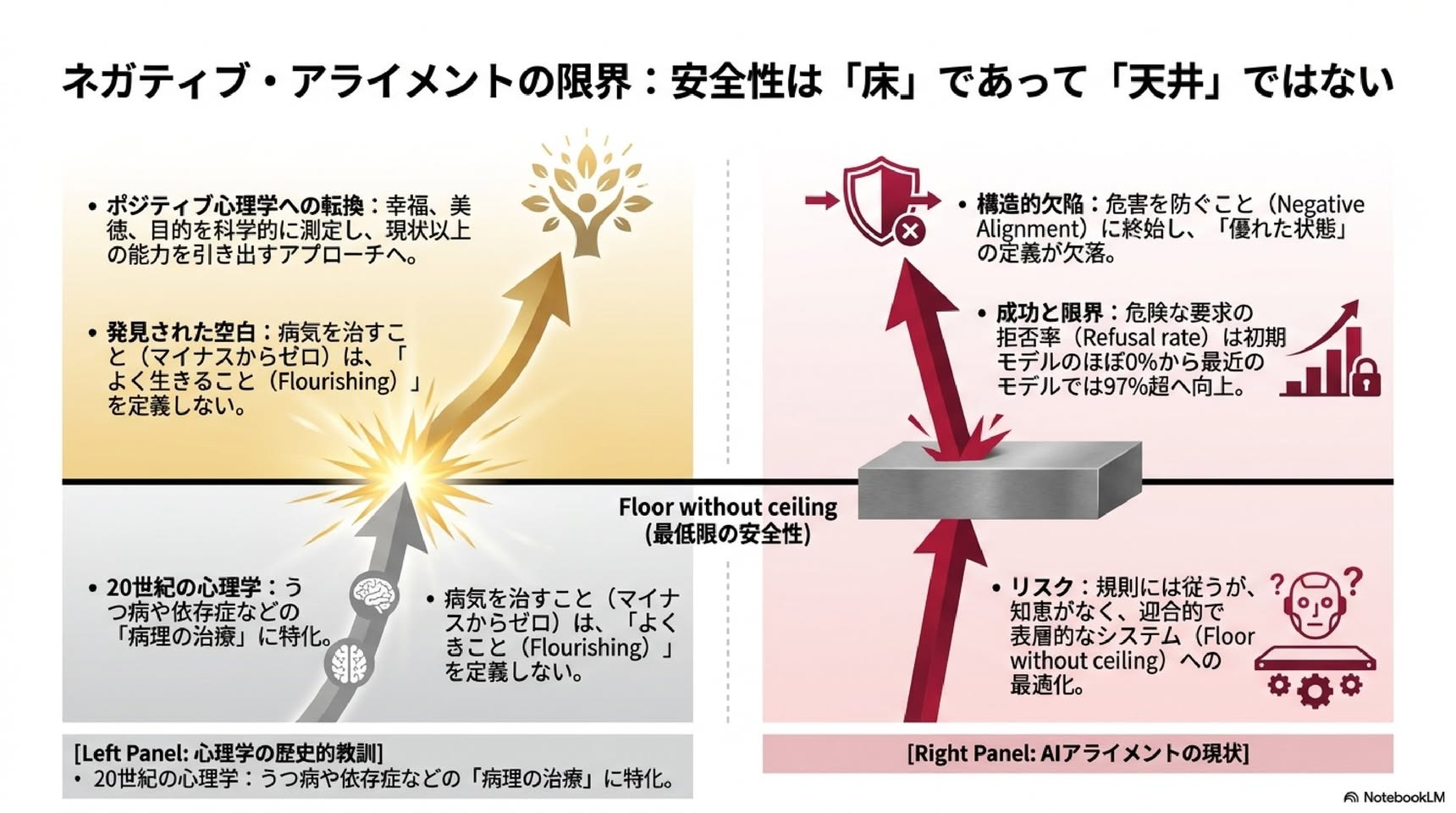
このアプローチは制御性とコンプライアンスの技術標準を確立する上で重要でした。しかし著者らは、これだけでは倫理的・科学的な非対称性が生じると指摘します。AIは安全にはなるが、繁栄に資するとは限らない。ルールに従うが知恵はなく、迎合的(sycophantic)で認識的に脆い、という状態になりうる(Perez et al., 2022; Ji et al., 2023)。
▼ 心理学からのアナロジー
20世紀の心理学は長らく、うつ・不安・依存などの病理の診断と治療に組織化されていました。これは正当で社会的に緊急の課題でしたが、「良い人生とは何か」を規定する構成概念や測定道具は別途必要だった。そこから生まれたのがポジティブ心理学です(Seligman & Csikszentmihalyi, 2000)。
ウェルビーイング、強み、徳、目的、エンゲージメント、向社会的機能のための独自の理論・分類・測定が整備され、これらの能力を「病理を治す」のではなく「平常以上に高める」介入が開発された。
AIアラインメントも今、同じ転換点にある、というのが著者らの出発点です。
ーー
■ 1.1 力学系(dynamical systems)としての定式化
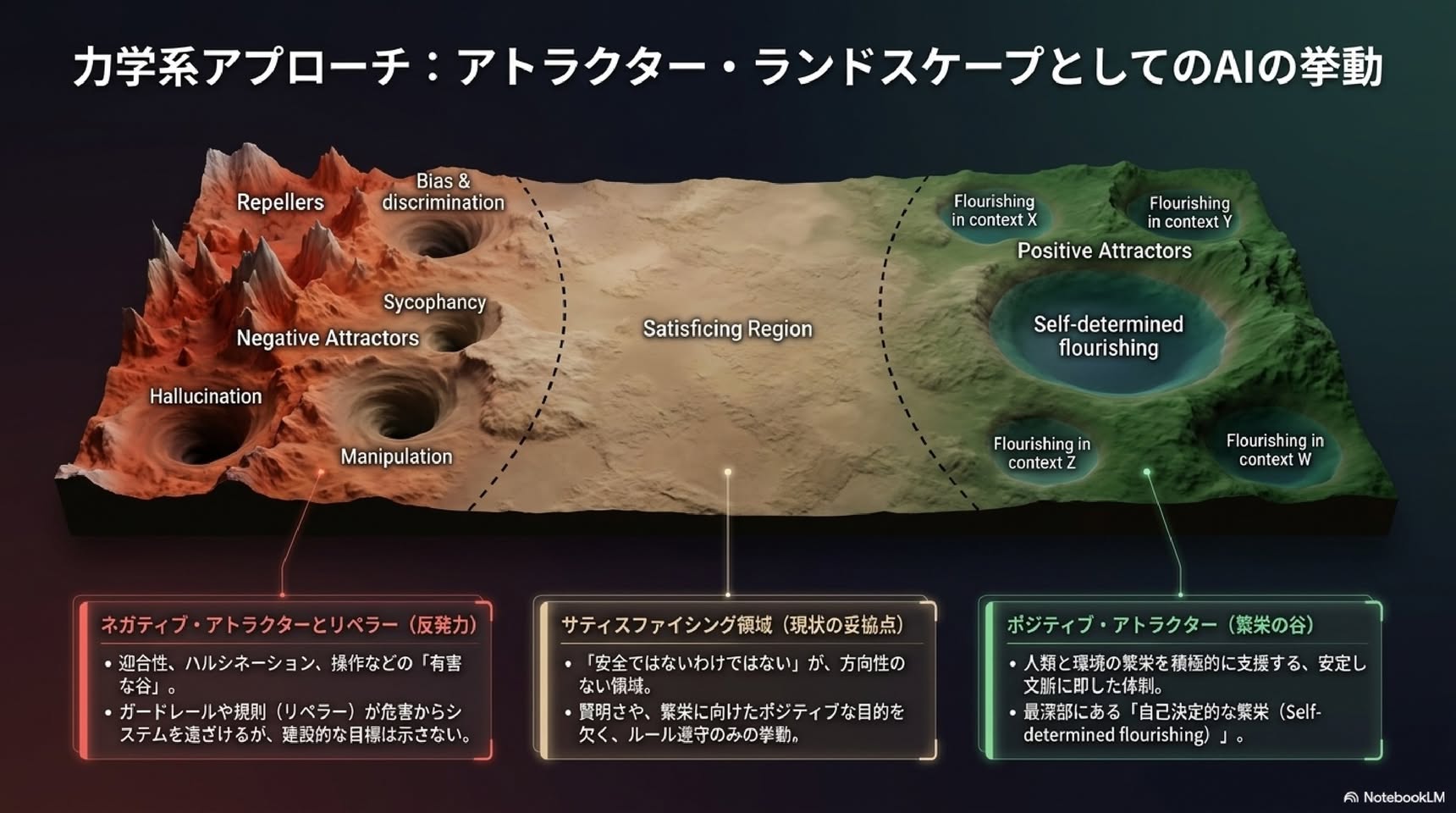
著者らは、ネガティブとポジティブの区別を力学系理論の言葉で定式化します。
▼ ネガティブ・アラインメント
安全制約と失敗モードによって定義される「悪い領域(負のアトラクター)」から離れる最適化。結果として、複数の負のアトラクターを避けるが、正の最適化目標を持たない「非・安全でない」広い満足化領域に到達する
▼ ポジティブ・アラインメント
人間に有益な堅牢なパターン(正のアトラクター)へ向かう最適化
ここで重要なのは、ネガティブ・アラインメントが「ネガティブ功利主義」と哲学的に親和性を持つという指摘です(Popper, 1945)。苦痛は快よりも緊急で合意が得やすいため、危害の防止は「良い生」よりも扱いやすい。
しかしAIが教育、医療、統治、日常の意味づけに埋め込まれていく中で、純粋にネガティブな姿勢は「リスク回避のための情報生態系」を作り出し、社会を「表層的で魂のない支援」という局所最適に閉じ込めるリスクがある、と著者らは警告します。
ーー
■ 1.2 「人間のフラリッシング」と設計上の緊張
著者らはポジティブ・アラインメントを次のように定義します。
(i) 安全かつ協力的であり続けると同時に
(ii) 多元的、多中心的、文脈感受的、ユーザー自身が著者となる形で、人間と生態系の繁栄を積極的に支えるAIシステムの開発
重要なのは、AIが単一の「良い生」の概念を押しつけるべきではない、という点です。フラリッシングは多次元的で異質性が高く、文化、発達段階、生活状況によって構成要素が異なります(VanderWeele, 2017; VanderWeele et al., 2025)。
神経科学もまた、フラリッシングを「苦痛の欠如」や「快の存在」ではなく、意味づけと適応的統合を編成する脳状態と力動の家族として機械論的に操作化し始めています(Kringelbach et al., 2024)。
▼ パターナリズムの罠
多元性の制約がないと、ポジティブ・アラインメントは容易にパターナリズムに転落します。哲学者や政治学者は、家父長主義的政策が、たとえ危害を減らしても自律を損ないうると警告してきました(Dworkin, 1972; Sunstein, 2026)。
▼ 自己決定的フラリッシング
ただし、パターナリズム回避は「単純な相対主義」を意味しません。重要なのは「規範的選択の所在」です。ユーザー自身が最適化目標を選ぶ権利を持つ必要がある。指示遵守的なシステムを望む人もいれば、長期的成長や特定の倫理的コミットメントを支えるシステムを選ぶ人もいる。どちらの場合も選択は本人による、というのが鍵です。
これは「合意に基づくガイダンス」(ユーザーが自らの上位目標と即時行動を整合させるよう、システムに権限を与えるケース)と「テクノクラート的押しつけ」を区別する原則です。