⑨幸福感データ分析への統計的アプローチ
ウェルビーイングハンドブック_第一章:序論、歴史、および測定
引き続き、測定について😊
これまでの中でも最もマニアックかもですが、幸せデータの統計処理について😊
ーー
あなたの「幸福度」は幻かもしれない:心理統計学が暴く5つの意外な真実
1.0 はじめに (Introduction)
幸福やウェルビーイング(Well-being)は、誰もが関心を寄せる普遍的なテーマです。私たちはしばしば、簡単なアンケートに答えたり、自分自身の内面を振り返ったりすることで、幸福度を測れると考えています。しかし、その測定は本当に信頼できるのでしょうか?「自分は今、10段階評価で7くらい幸せだ」と結論づけるとき、その数字は一体何を意味しているのでしょうか。
心理学の研究者たちは、この「幸福を測る」という行為自体に、数々の複雑な問題が潜んでいることを発見しました。私たちの直感に反して、測定方法のわずかな違いや、データの見えざる特性によって、幸福に関する結論はいとも簡単に歪められてしまうのです。一見すると明白に見えるデータが、実は全くの誤解へと私たちを導いている可能性さえあります。
この記事では、心理学者マイケル・アイドの研究に基づき、ウェルビーイングに関するデータ分析から明らかになった、特に驚くべき5つの発見をご紹介します。これらの洞察は、幸福に関する研究の奥深さを示し、あなた自身の「幸せ」についての考え方を変えるきっかけとなるかもしれません。
ー
2.0 意外な発見1:「効果あり」はただの統計的蜃気楼?
ある研究者が、人々のウェルビーイングを高めるための介入プログラムを開発したとします。プログラム実施後、参加前のスコアが低かった人ほど、スコアの伸びが大きかったという結果が出ました。これは「最も助けを必要としていた人々に、最も効果があった」という素晴らしい結論に思えます。しかし、ここに一つ目の大きな罠が潜んでいます。
この結果は、プログラムに全く効果がなかったとしても起こり得る、「純粋な統計的アーティファクト(methodological artifact)」、つまり見せかけの結果かもしれないのです。その原因は「測定誤差」にあります。科学における測定には、完璧なものは存在しません。例えば、同じ体重計で繰り返し体重を測っても、乗り方によってわずかに数値が変動するように、どんな測定にも「ノイズ」と呼ばれるランダムな影響が含まれます。
心理学の研究では、この測定誤差が原因で、介入前のスコアとスコアの変化量との間に、見せかけの負の相関(低い人は伸び、高い人は伸び悩むように見える関係)が生まれることが示されています。つまり、介入プログラムが全くの無意味であったとしても、測定誤差が存在するだけで、「効果があった」かのようなデータが作り出されてしまうのです。これは、私たちがデータにいかに簡単に騙されうるかを示す衝撃的な例と言えるでしょう。これは、自己啓発書やニュースで目にする「効果実証済み」という言葉を、少しだけ疑いの目で見るべき理由を教えてくれます。
ー
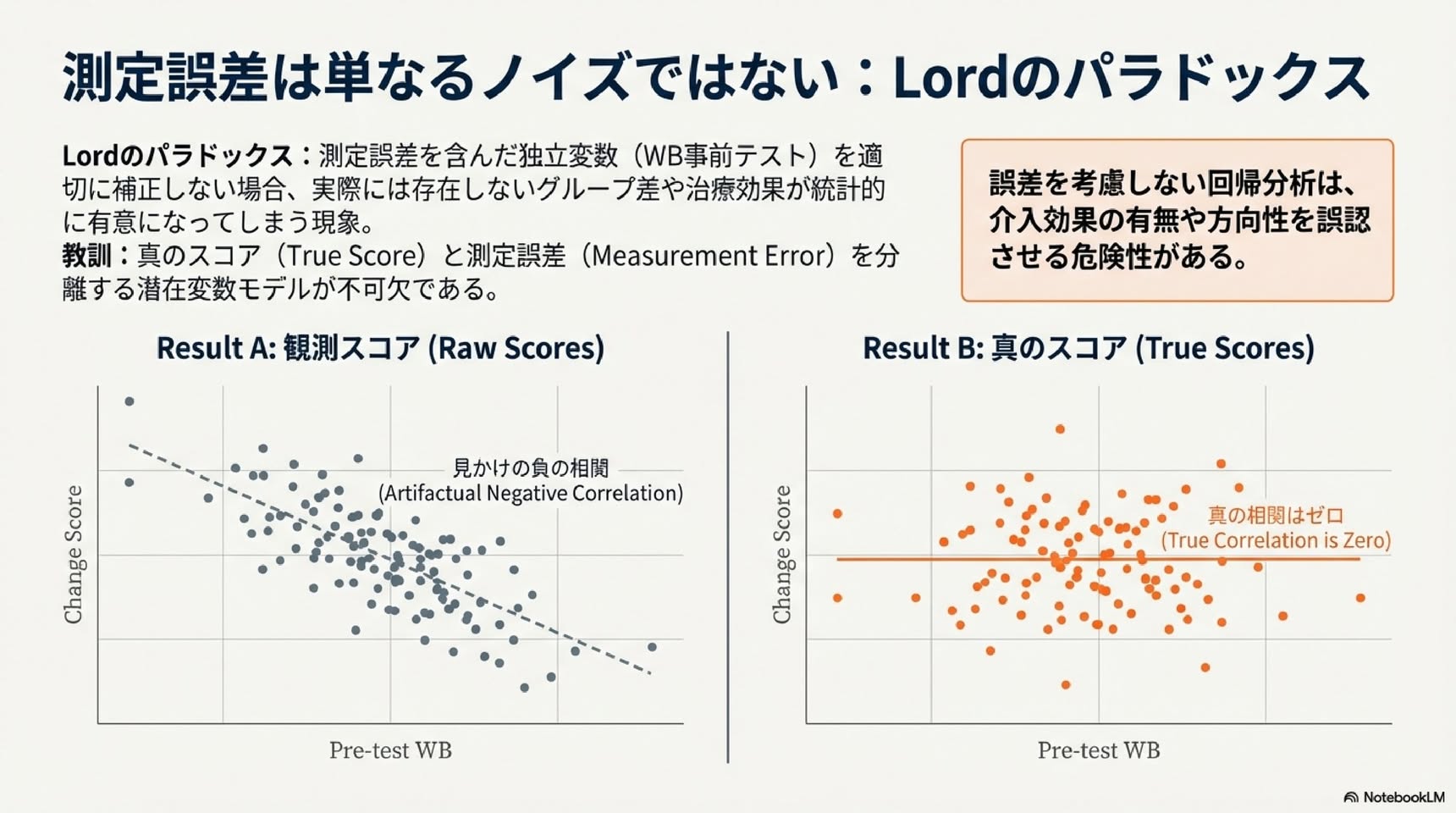
3.0 意外な発見2:公平な比較はなぜ難しいのか - 「ロードのパラドックス」
次に紹介するのは、比較研究に潜む「ロードのパラドックス」と呼ばれる現象です。ここでも、ウェルビーイングを高める介入プログラムの効果を測定する場面を考えてみましょう。ただし今回は、参加者をランダムに割り当てるのではなく、本人が希望して「介入グループ」か何もしない「対照グループ」かを選んだとします。
この場合、もともとウェルビーイングへの関心が高い人(そしておそらくスコアも高い人)が、介入グループに集まりやすいかもしれません。研究者はこの偏りを補正するため、統計的に介入前のスコアを考慮して分析しようとします。しかし、まさにこの「補正」が問題を引き起こします。介入前のスコアに含まれる測定誤差が、存在しないはずの治療効果を人工的に作り出してしまうのです。
このパラドックスの驚くべき点は、介入グループと対照グループの両方の「真の」ウェルビーイングスコアが全く同じだけ上昇した(つまり、介入効果がゼロだった)としても、分析結果では「介入グループの方が有意に効果があった」と示される可能性があることです。これは、統計分析の難しさを浮き彫りにします。
測定誤差がない変数(例:グループ分け)の効果でさえ、別の変数(例:介入前のスコア)の測定誤差を適切に補正しないと、その結果が歪められてしまう可能性があるのです。
ー
4.0 意外な発見3:あなたの幸福は「尺度」の上にある?それとも「タイプ」に分類される?
研究者はウェルビーイングを理解するために、異なる概念モデルを用いています。私たちは通常、幸福を「低い」から「高い」まで続く一本の物差し(尺度)の上にあるものと考えがちです。これは「次元モデル」と呼ばれます。
しかし、もう一つの考え方として「類型モデル」があります。これは、人々を単一の尺度で順位付けするのではなく、異なる特徴を持ついくつかの「タイプ(クラス)」に分類するアプローチです。
例えば、「結婚」「余暇活動」「仕事」という3つの領域における人生の満足度を調べたとしましょう。次元モデルなら、これらを合計して総合的な満足度スコアを算出するかもしれません。しかし、類型モデルを用いると、人々は次のような異なるクラスに分類される可能性が見えてきます。
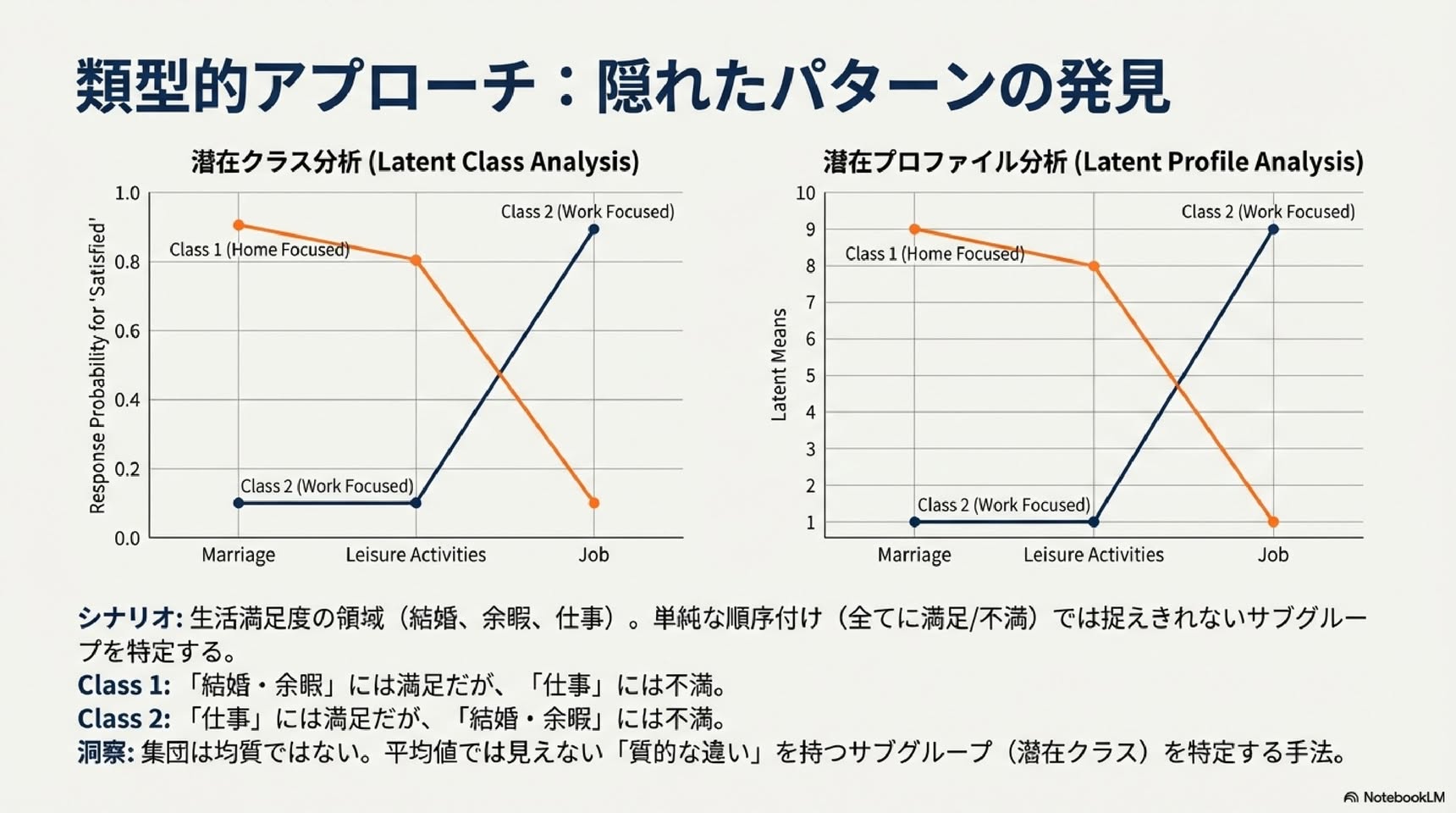
クラス1: 結婚と余暇活動への満足度は高いが、仕事への満足度は低いタイプ。
クラス2: 仕事への満足度は高いが、結婚と余暇活動への満足度は低いタイプ。
この区別は非常に重要です。なぜなら、単に「より幸福」か「そうでないか」を問うのではなく、人生のどの領域で満足感を得ているかという「幸福のパターン」そのものに意味があることを示唆しているからです。あなたの幸福は、一本の物差しでは測れない、より複雑なプロファイルを持っているのかもしれません。
ー
5.0 意外な発見4:「総合的な幸福度」という一つの指標は、何を予測するかで意味が変わる
ウェルビーイングは多面的な概念であり、一般的に「人生の満足度(LS)」「ポジティブ感情(PA)」「ネガティブ感情(NA)」といった複数の要素で構成されています。研究者たちはしばしば、これらの要素を組み合わせて一つの「総合的なウェルビーイング(WB)」スコアを作ろうと試みますが、ここにも興味深い発見があります。
「形成的測定モデル」というアプローチでは、特定の「結果」を予測するために、LS、PA、NAの最適な組み合わせをその都度作り出します。ここでの重要な点は、この「総合的なWB」の意味は、何を予測したいかによって変化するということです。
例えば、このモデルを使って次のような予測を行うとします。
創造性(Creativity) を予測する場合:「ポジティブ感情(PA)」がより重視された構成の幸福度が、最適な予測因子として作り出されるかもしれません。
論理的思考課題(Reasoning tasks) の成績を予測する場合:逆に、「ネガティブ感情(NA)」がより強く影響する構成の幸福度が、最適な予測因子として作り出されるかもしれません。
これは、「総合的な幸福」に万能のレシピは存在しないことを意味します。私たちが何を達成したいか、どのような文脈にいるかによって、理想的な幸福の構成要素は変化するのです。ある状況で最適な心の状態が、別の状況ではそうではないかもしれない、という柔軟な視点を提供してくれます。
ー
6.0 意外な発見5:本当のあなたを知っているのは誰?自己評価と他者評価のズレが語ること
ウェルビーイング研究で最もよく使われるのは自己報告ですが、その妥当性は常に問われます。「他者からの評価と比べることで、より正確な姿が見えるのでは?」と考えるのは自然なことです。しかし、ここでも単純な話ではありません。
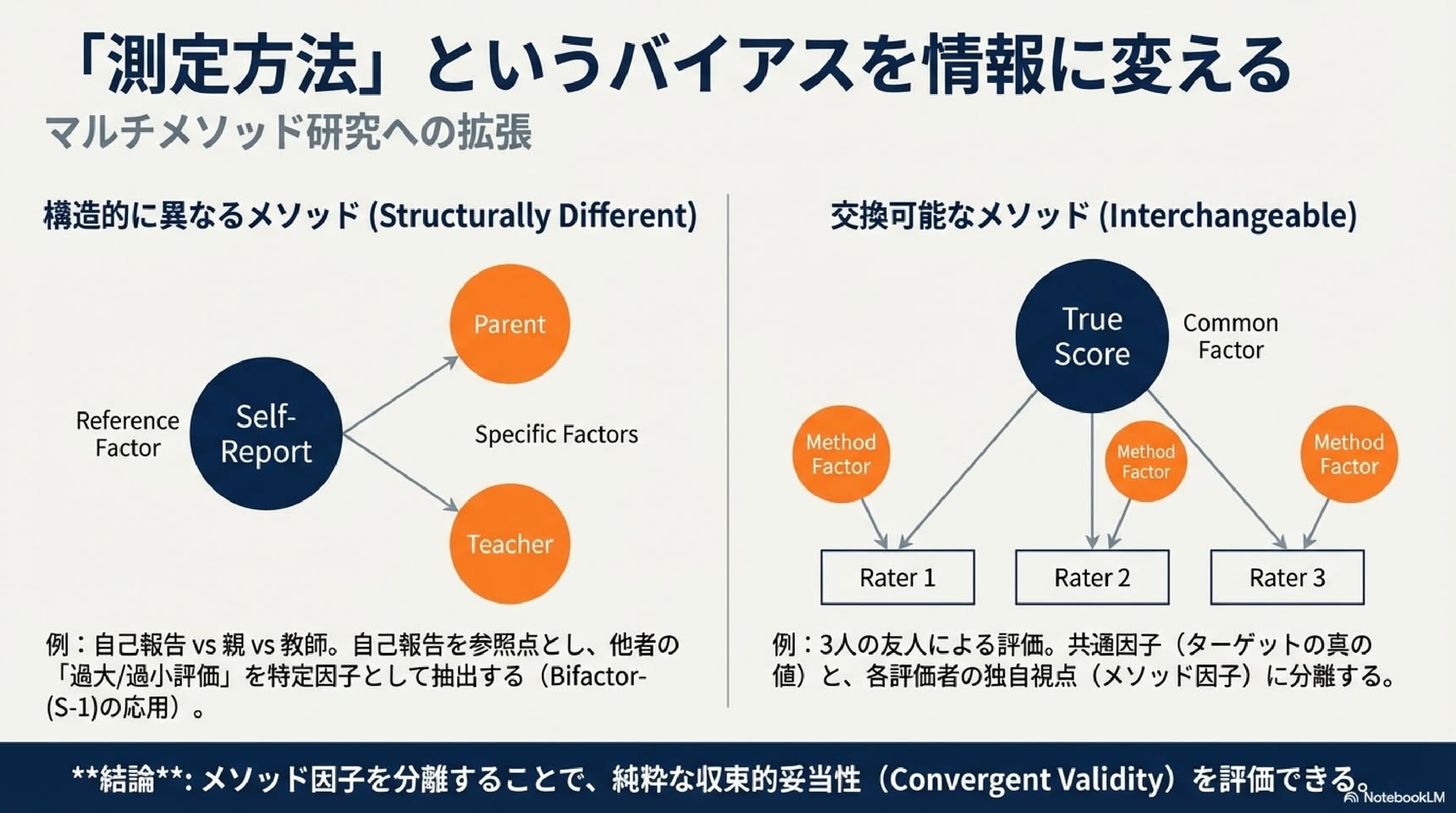
研究では、評価者を2つのタイプに区別します。
交換可能な評価者: 同じような立場の人々。例えば、あなたの友人複数名があなたの幸福度を評価する場合。
構造的に異なる評価者: それぞれが異なる役割や視点を持つ人々。例えば、あなた自身(自己報告)、あなたの親、そしてあなたの先生が評価する場合。
ここでの重要な洞察は、構造的に異なる評価者(自分、親、先生など)の間で見られる評価のズレは、単なる「誤差」ではないということです。それは、それぞれの視点が持つ本質的な情報を含んでいます。親は家庭でのあなたを見ており、先生は学校でのあなたを見ています。そして、あなた自身は自分の内的な経験を知っています。これらの視点はどれも「真実」の一部であり、互いに異なる情報を提供しているのです。
したがって、目指すべきは唯一の「正しいスコア」を見つけることではありません。むしろ、なぜこれらの視点が異なるのかを理解し、それぞれの評価があなたのウェルビーイングのどのような側面を照らし出しているのかを探求することの方が、はるかに有益なのです。
ー
7.0 まとめ (Conclusion)
ここまで見てきたように、ウェルビーイングの測定は、私たちが思うよりもはるかに複雑で、落とし穴に満ちています。一見すると明白なデータも、測定誤差や分析モデルの前提を疑うことなく受け入れてしまえば、深刻な誤解につながりかねません。
統計モデルと聞くと、専門家のためだけの難解なツールに思えるかもしれません。しかし、それらは幸福のような主観的な経験の真実に迫るために不可欠な羅針盤なのです。データに潜む見えざる影響を理解することで、私たちはより深く、より正確に人間の幸福を探求することができるようになります。
この複雑な真実を踏まえたとき、私たちは自分自身の、そして社会全体の幸福という捉えどころのない概念と、どう向き合っていくべきなのでしょうか。その問いこそが、これからのウェルビーイング研究の核心となっていくのかもしれません。
ーーー
Eid, M. (2018). Statistical approaches to analyzing well-being data. In E. Diener, S. Oishi, & L. Tay (Eds.), Handbook of well-being. Salt Lake City, UT: DEF Publishers. DOI:nobascholar.com
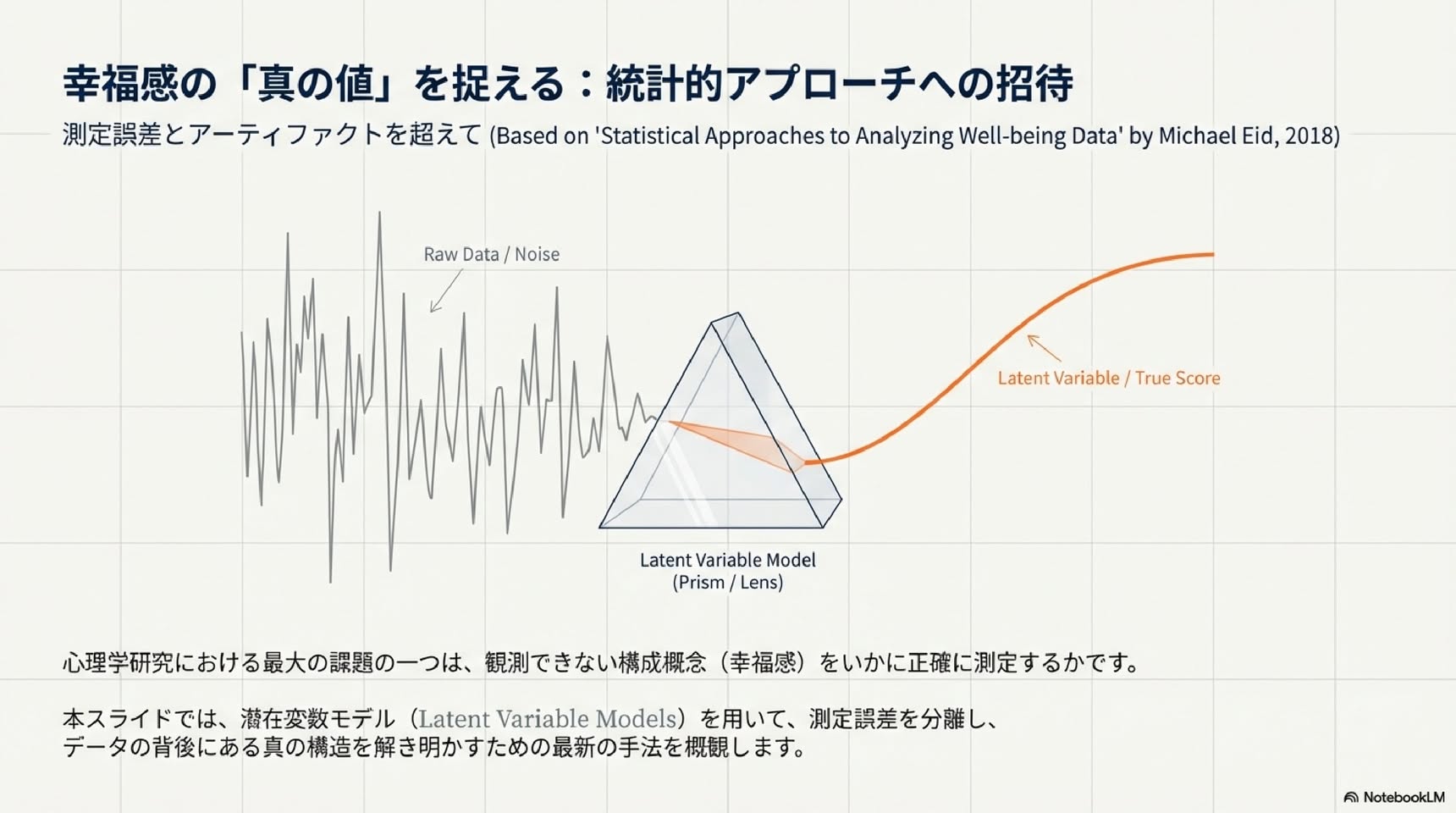
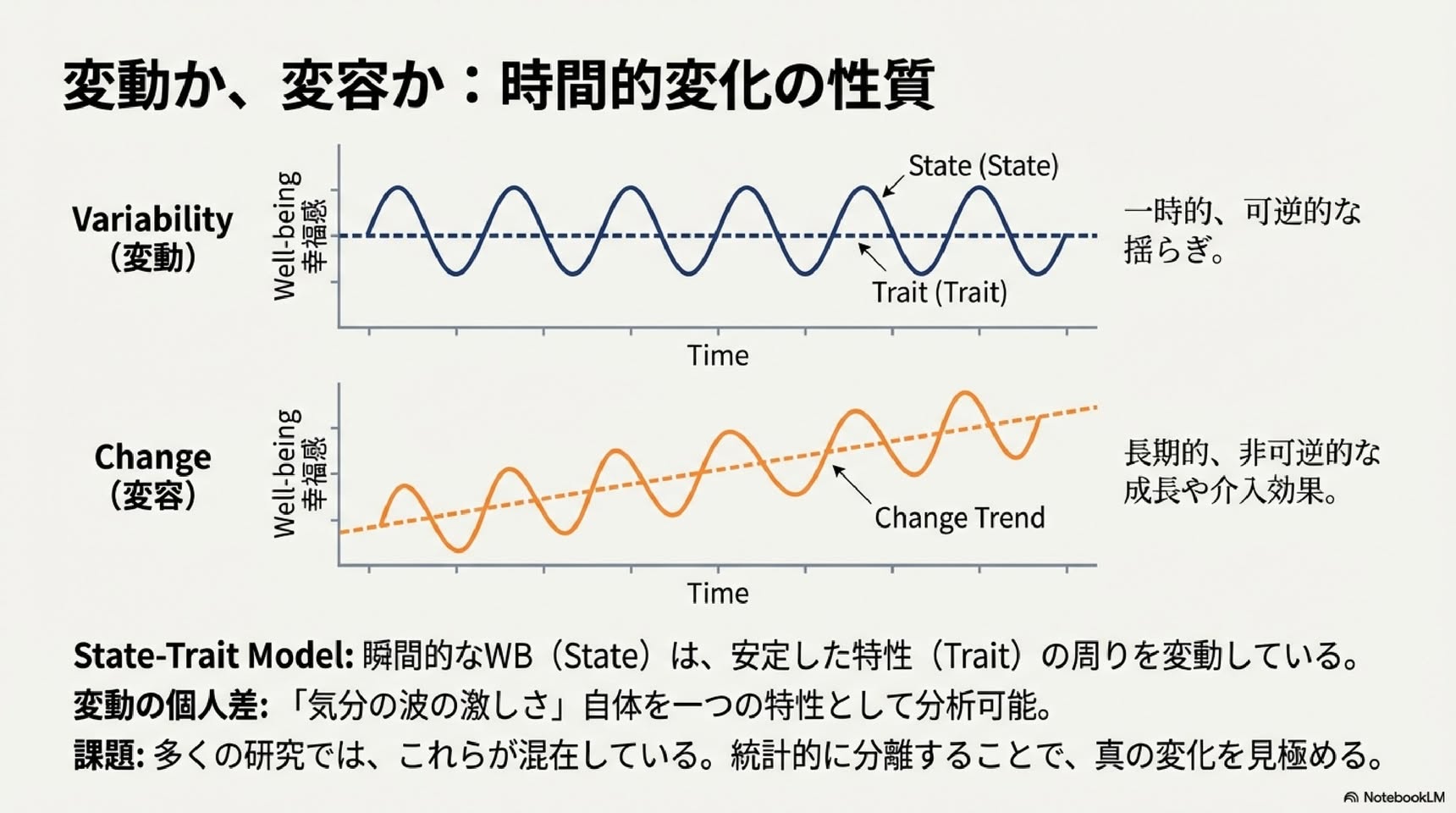
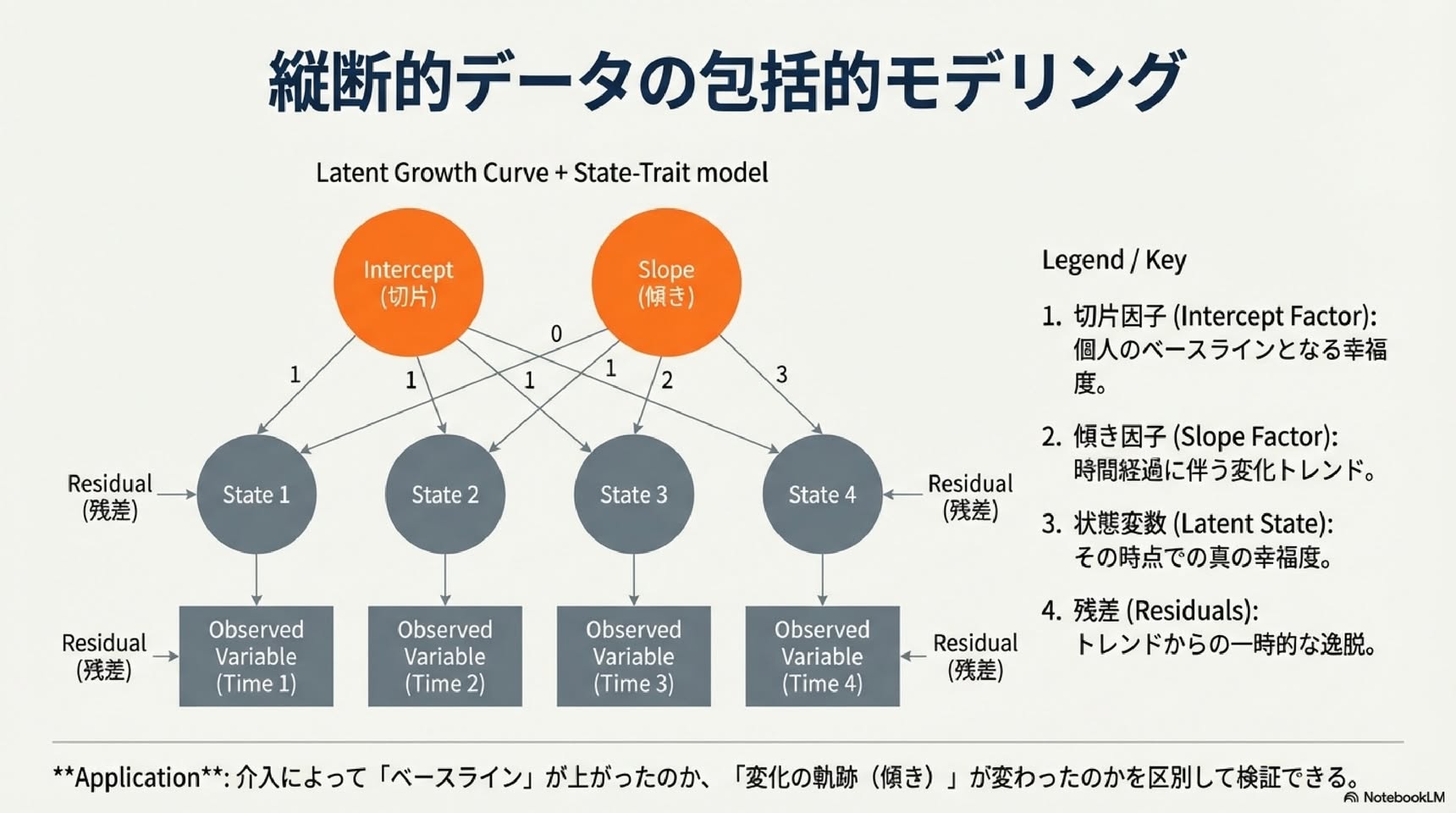
本章では、ウェルビーイング(WB)研究における現代的な潜在変数モデルの概要を述べる。測定誤差の重要性と測定誤差によって生じうる方法論的アーティファクトについて簡潔に紹介した後、四種類の潜在変数モデルの基本原理を説明する:項目応答理論、潜在クラス分析、因子分析、潜在プロファイル分析である。次に、多次元データ構造に対する潜在変数モデルについて論じ、これらのモデルを用いて一般的なWB測定指標や側面特異的因子(facet-specific factors)を定義する方法を示す。これらのモデルが多方法論的WB研究にどのように適用できるか、またこの文脈において収束的妥当性と判別的妥当性をどのように測定できるかを指摘する。最後に、WBにおける変動性と変化を分析するための非常に一般的なモデルを提示し、このモデルおよびその特殊ケースがWB研究にどのように応用できるかを論じる。
キーワード:潜在変数モデル、項目応答理論、古典的テスト理論、潜在クラス分析、潜在プロファイル分析、確認的因子分析、測定誤差、g因子、二因子モデル、縦断データ分析

AIさんによる動画解説😊
https://youtu.be/3kYQ_ikn3Dg
幸福感データ分析への統計的アプローチ
■ 論文の概要
この論文は、幸福感(ウェルビーイング)研究における現代的な統計モデルについて解説したものです(Eid, 2018)。測定誤差の重要性から始まり、潜在変数モデル(観察できない変数を扱うモデル)の基本原理、多次元データの分析方法、縦断的変化の測定まで、幅広くカバーしています。
ーー
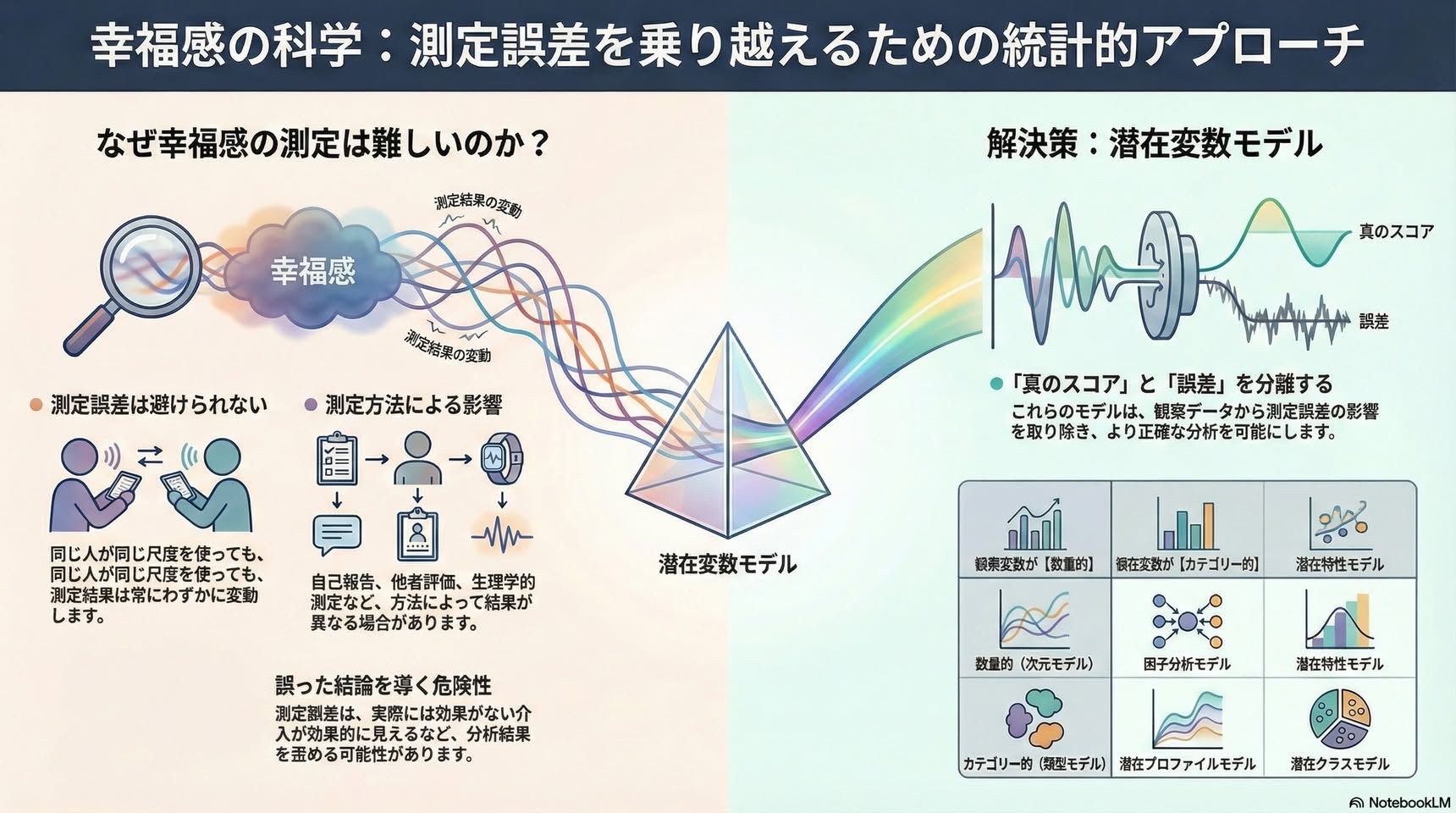
■ なぜ測定誤差を考慮することが重要なのか
▼ 測定誤差は避けられない
・科学的測定において、測定誤差(同じものを測っても毎回結果が少しずつ異なること)は避けられません
・古典的テスト理論では、観測されたスコア=真のスコア+測定誤差、と分解します
・真のスコアとは、同じ個人を何度も測定して平均した値のことです
▼ 測定誤差が引き起こす問題
測定誤差を無視すると、様々な方法論的アーティファクト(見かけ上の効果)が生じます:
・介入研究の例:幸福感介入の前後で変化量と事前スコアの相関を調べたとき、測定誤差があると実際には無相関でも負の相関が見られてしまいます(Rogosa, 1995)
・準実験研究の例:自己選択による群分けがある場合、測定誤差を適切に補正しないと、実際には効果がないのに介入効果が見られる「ロードのパラドックス」が生じます(Lord, 1967)
・これらの例は、測定誤差の補正が幸福感研究において極めて重要であることを示しています
ーー
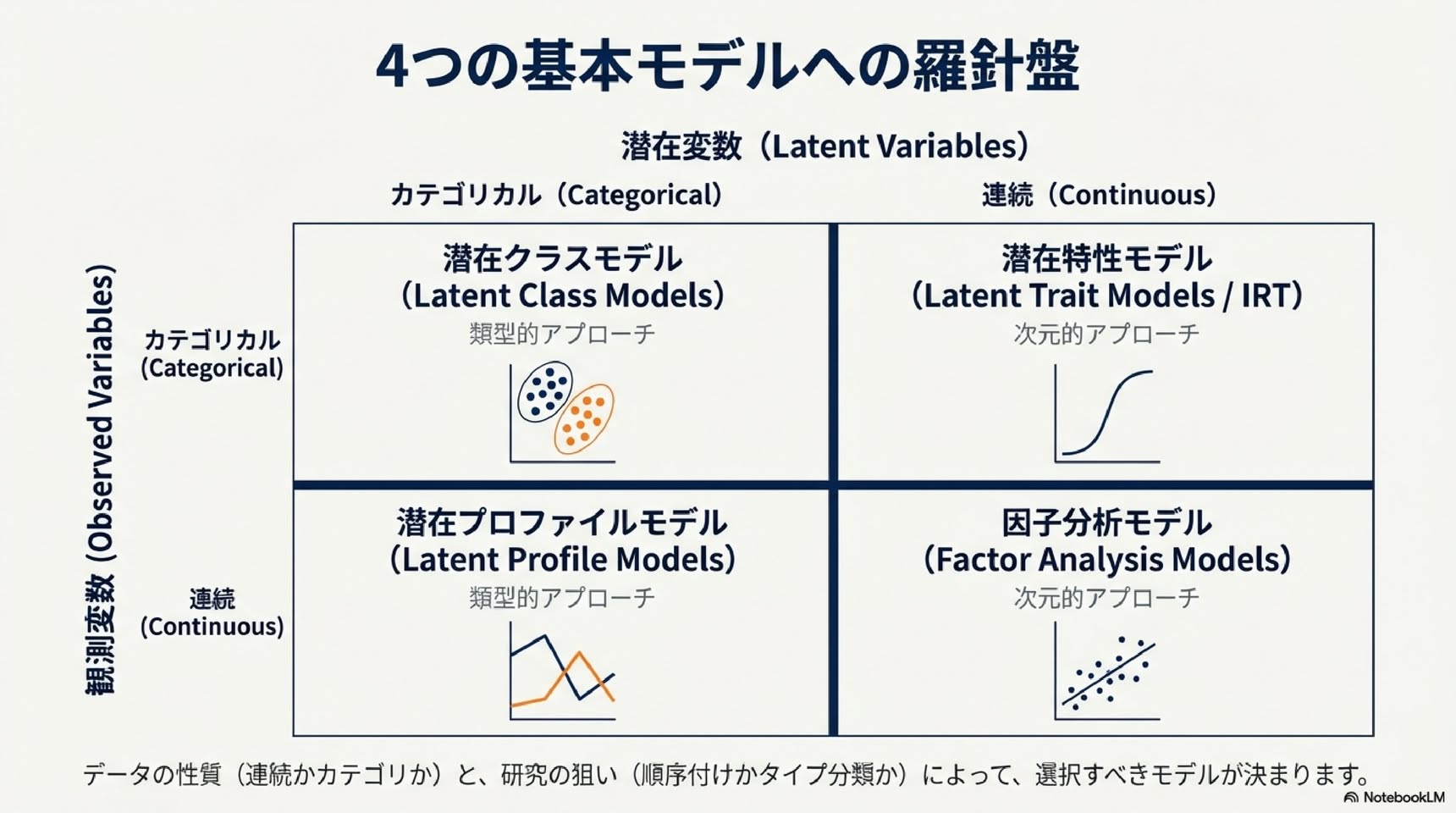
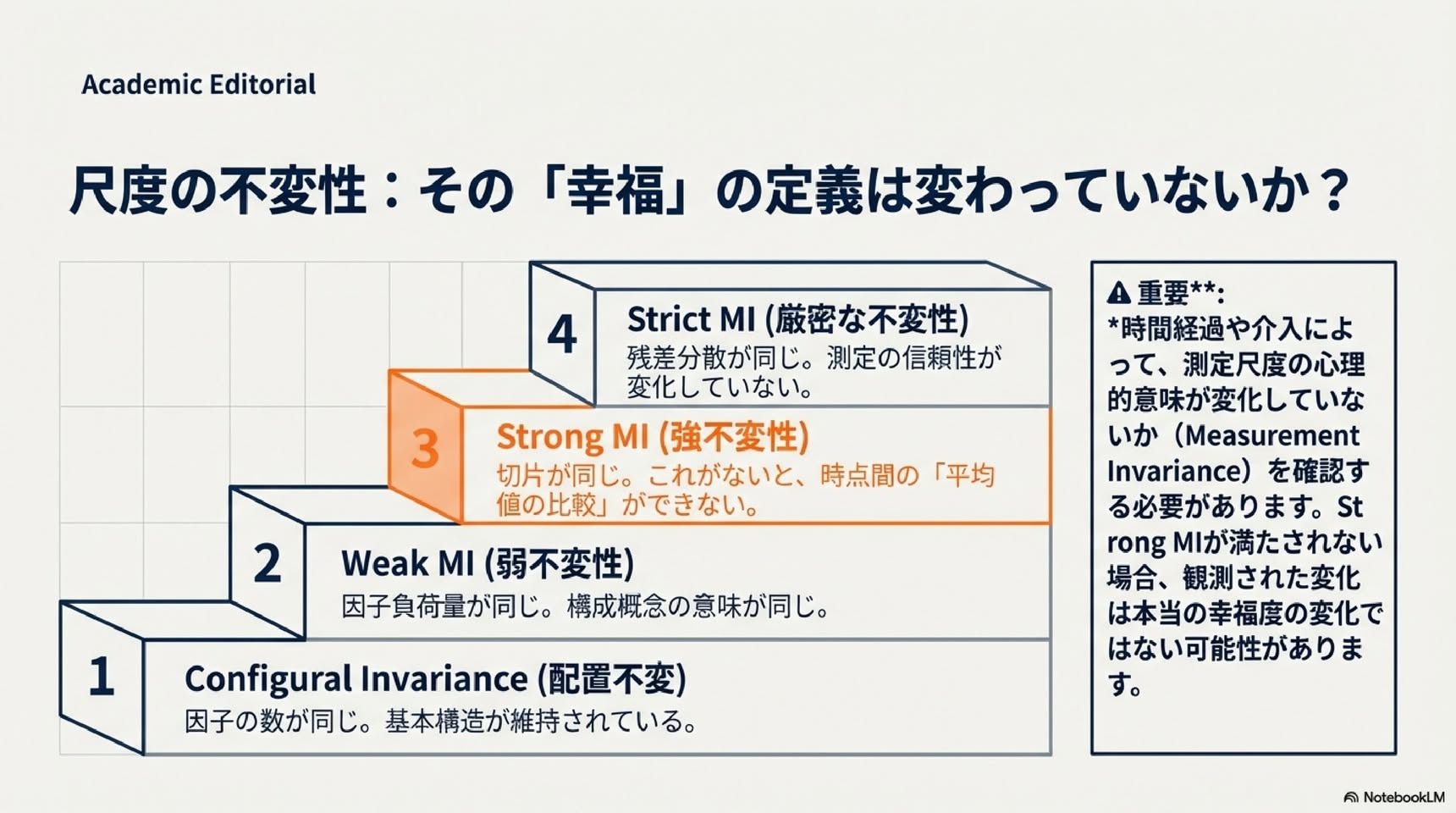
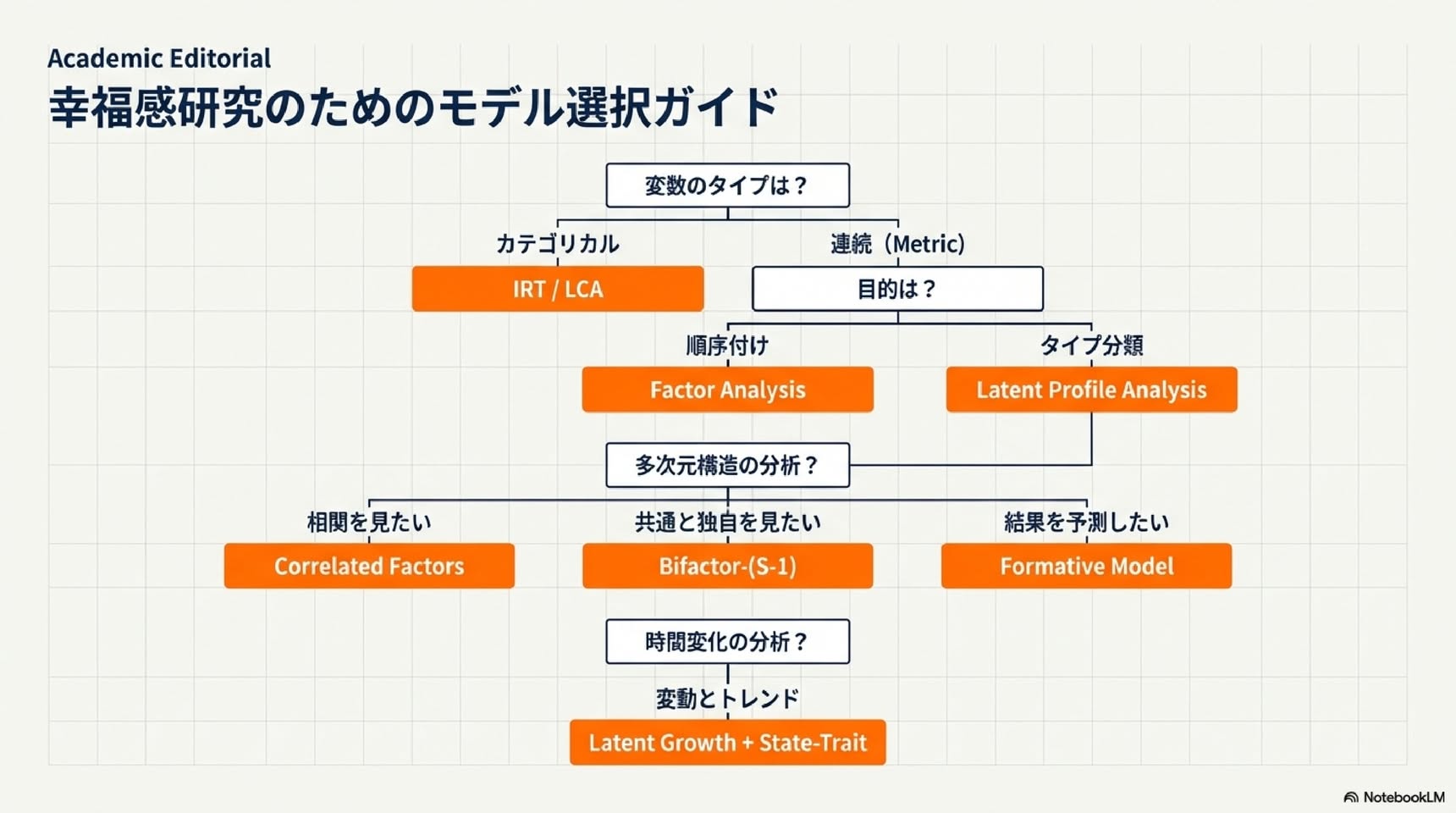
■ 測定誤差をどう考慮するか:4つの潜在変数モデル
潜在変数モデルは、観測変数(実際に測定できる変数)の種類と潜在変数(観測できない誤差のない変数)の種類によって4つに分類されます(Bartholomew & Knott, 1999):
▼ 1. 潜在特性モデル(観測変数:カテゴリカル/潜在変数:連続)
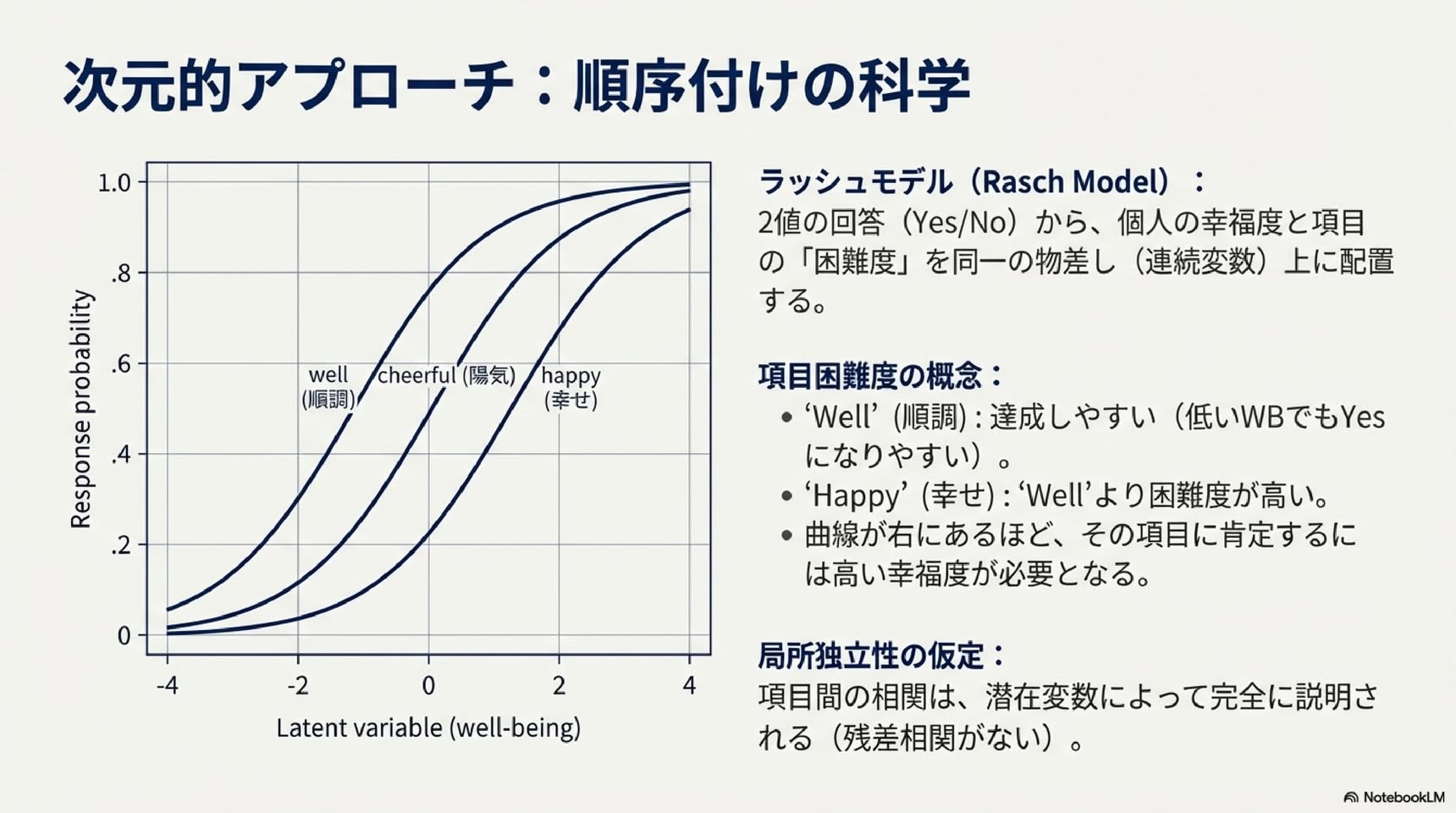
・代表例:ラッシュモデル(Rasch, 1960)
・二値の項目(はい/いいえ)で連続的な潜在次元を測定します
・例:「元気」「陽気」「幸せ」という3項目で幸福感を測定
・各項目の「はい」と答える確率は、その人の幸福感レベル(潜在変数)によって決まります
・項目にはそれぞれ「困難度」があり、幸福感が高くないと「はい」と答えにくい項目もあります
・項目間の相関は、同じ構成概念(潜在変数)を測定しているから生じますが、測定誤差のため完全には相関しません
▼ 2. 潜在クラス分析(観測変数:カテゴリカル/潜在変数:カテゴリカル)
・Lazarsfeld & Henry(1968)が開発
・母集団がいくつかのサブグループ(潜在クラス)から構成されると仮定します
・例:「結婚」「余暇」「仕事」の満足度を測定した場合
・すべての項目を同じ次元上に順序づけることが理論的・実証的に不可能な場合に適しています
・各個人がどのクラスに属するかは未知ですが、推定可能です
▼ 3. 因子分析モデル(観測変数:連続/潜在変数:連続)
・連続的な観測変数(尺度得点など)を分析します
・潜在特性モデルと似ていますが、項目特性曲線が直線になります
・観測値=因子によって予測される部分+測定誤差、と分解されます
・因子が観測変数間の相関を完全に説明すると仮定します
▼ 4. 潜在プロフィール分析(観測変数:連続/潜在変数:カテゴリカル)
・Lazarsfeld & Henry(1968)が開発
・潜在クラス分析の連続変数版です
・各サブグループは、観測変数の平均値のプロフィールによって特徴づけられます
・古典的モデルでは、観測変数は各潜在クラス内で正規分布し、独立であると仮定します
ーー
■ 多次元的な幸福感の構造をどうモデル化するか
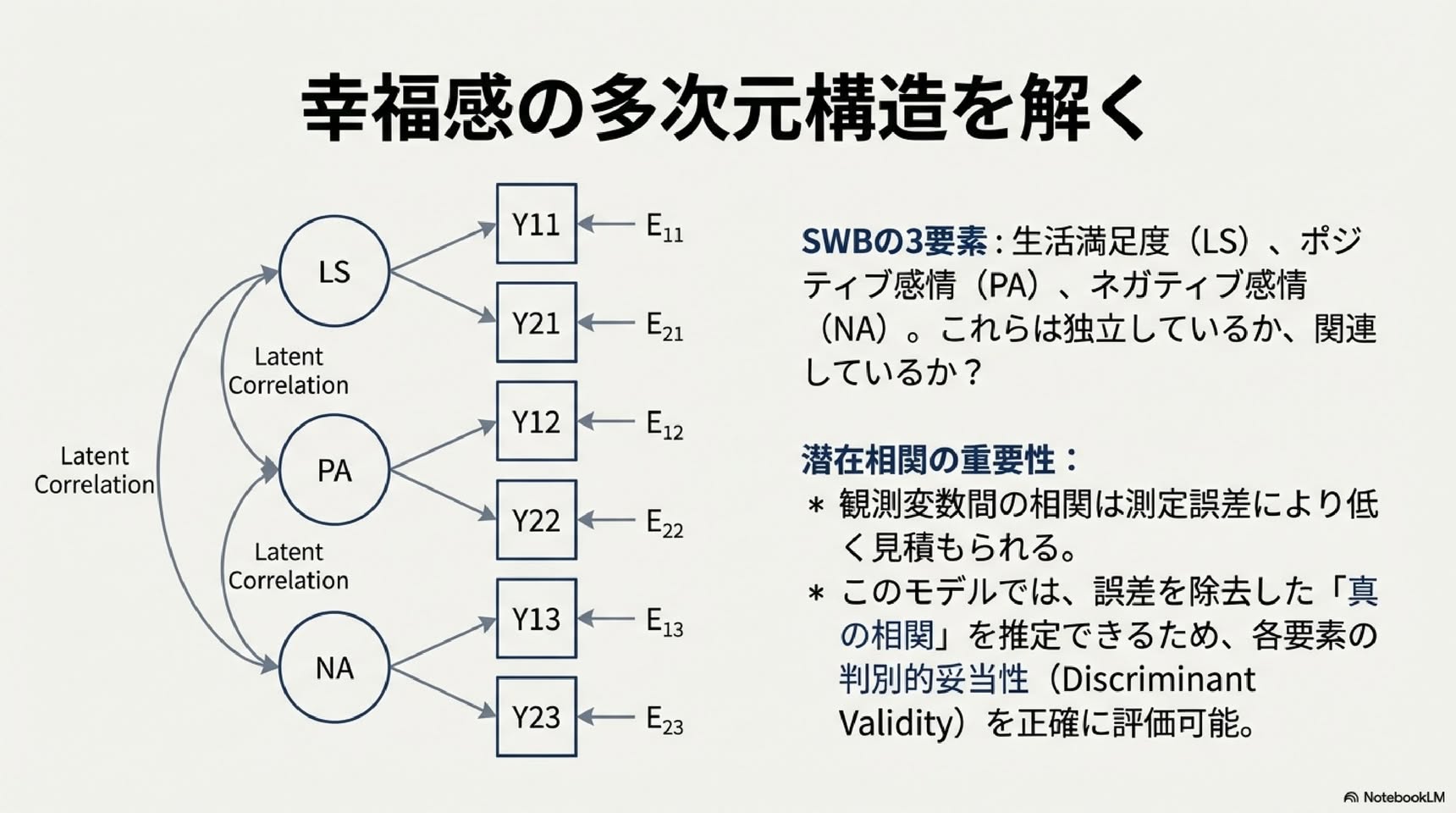
主観的幸福感(SWB)は通常、人生満足度(LS)、ポジティブ感情(PA)、ネガティブ感情(NA)の3つの構成要素から成ります。これらの関係を分析するため、多次元モデルが必要です。
▼ モデルa:相関のある因子モデル
・3つの潜在変数(LS、PA、NA)を設定し、それぞれに2つの指標を配置
・3つの因子間の潜在相関を分析できます
・この相関は測定誤差に歪められていないため、観測変数間の相関より正確です
・このモデルで以下を検討できます:
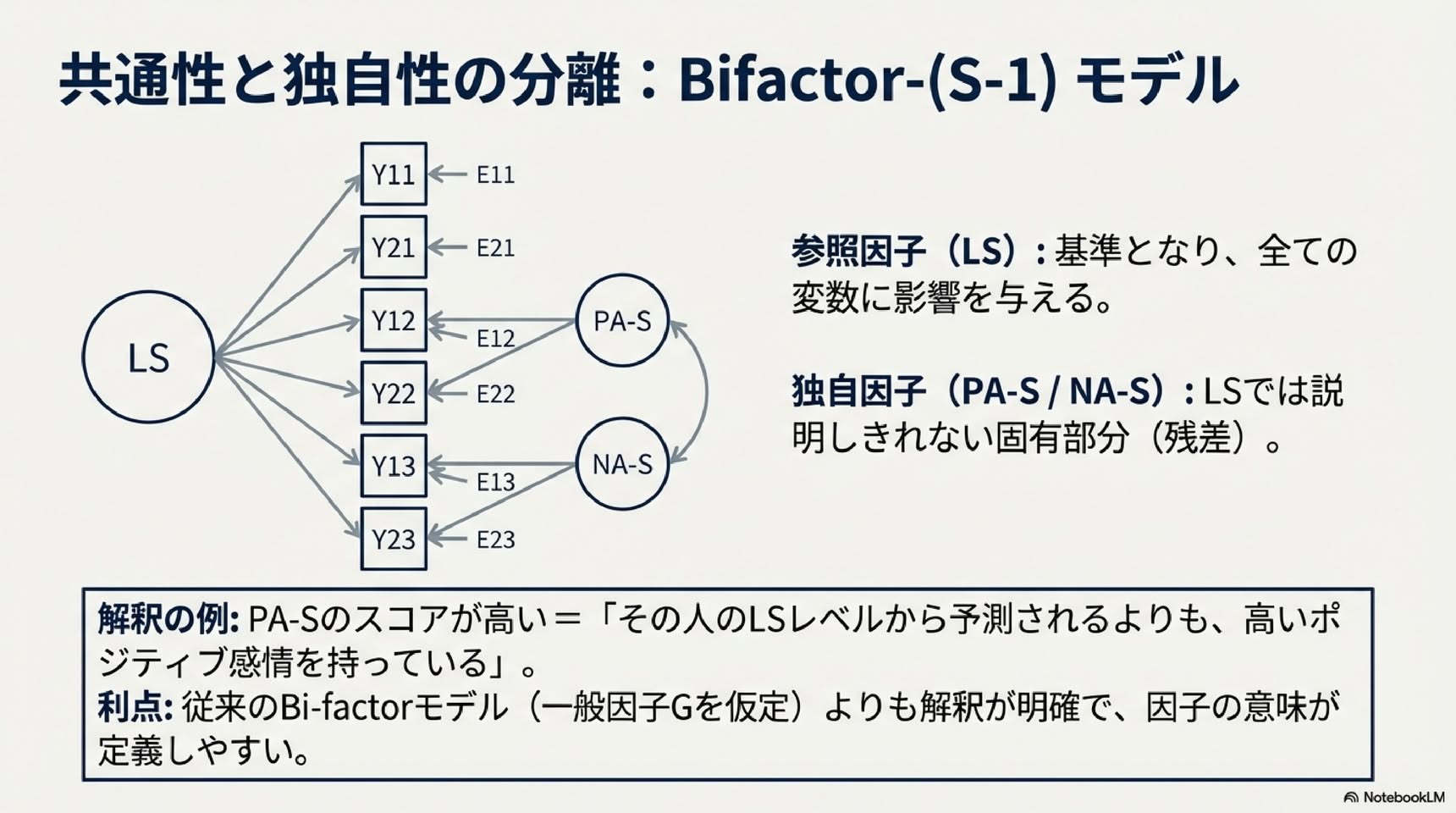
▼ モデルb:二因子(S-1)モデル
・ある構成要素(例:LS)を参照因子として選び、他の構成要素の特定部分を定義します
・PA-S(PAの特定因子)=LSでは予測できないPAの部分
・NA-S(NAの特定因子)=LSでは予測できないNAの部分
・特定因子の解釈:
・PA-SとNA-Sの相関は偏相関(LSの影響を除いた相関)を示します
・因子による説明分散を比較することで、構成要素の特異性の程度を評価できます
▼ モデルc:二因子モデル
・LS因子にも特定因子を定義し、すべての特定因子を無相関にした場合、これは二因子モデルになります
・左側の因子はLS因子ではなく、一般因子(G因子)になります
・ただし、構成要素が互換性のない場合(LSとPAとNAは理論的に異なる構成概念)、二因子モデルは問題のある結果を生み、G因子の意味が明確ではなくなります(Eid et al., 2016)
▼ モデルd:共通の独立変数を持つモデル
・すべてのSWB観測変数を別の独立変数(例:フラーリッシング)に回帰させます
・各側面の残差因子は、独立変数では予測できない部分を示します
・正のLS-S値:そのフラーリッシングスコアから期待されるより高いLS
・側面特異性が大きい場合、フラーリッシングとSWBは異なる構成概念であることを示します
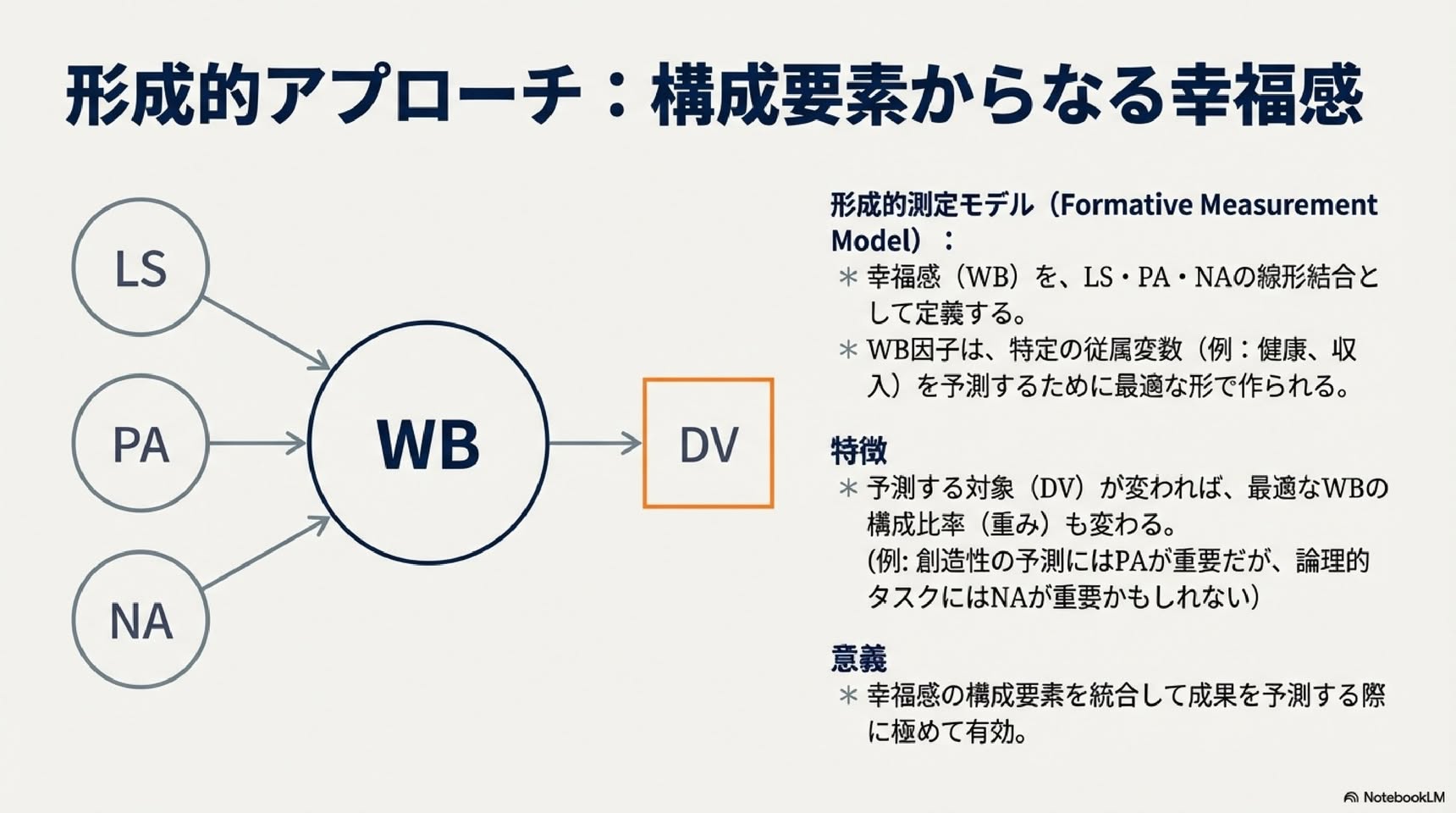
▼ モデルe:形成的測定モデル
・一般的WB因子を3つの側面の線形結合として定義します
・この因子は、考慮される従属変数(健康、収入など)に対して、3つの側面の最良の組み合わせとなります
・WB因子の意味は従属変数によって変わります
・形成的因子は心理学ではまだ珍しいですが、今後の幸福感研究において有望です(Willoughby et al., 2014)